The world before and after Transformers, and how their unsupervised and parallel learning capabilities unleashed the new era of AI.
How does intelligence work? What truly sets humans apart in terms of their intelligence? And how can we bridge the gap between human and artificial intelligence? These are fundamental questions that have captivated the minds of researchers, leading to remarkable advancements in the field.
The underlying notion is that the human brain functions as a neural network, albeit with slower neurons. Based on this premise, it has been theorized that training a large neural network on a big enough dataset could unlock the potential of creating an "intelligent" machine capable of executing complex tasks and solving intricate problems. In recent years, this vision has transformed into a tangible reality.
A Leap Towards the Holy Grail
Many industry experts consider unsupervised learning to be the holy grail of machine learning, holding the key to realizing Artificial General Intelligence (AGI). In cases where unsupervised learning is not feasible, alternative methods relying on human intervention become necessary. Take supervised learning where training datasets need to be meticulously labeled; as an example of a model that processes photos, each photo in the training dataset must be accompanied by descriptive labels (e.g. identifying whether the photo contains a car or an airplane). Producing these labeled datasets is a costly and time-consuming endeavor. Considering that a significant portion of the world's data remains unlabeled, conventional learning techniques fall short in generating models with the remarkable capabilities of the human brain. This is where unsupervised learning steps in, enabling the utilization of vast unlabeled datasets to train large neural networks capable of uncovering intricate patterns buried deep within the data—patterns that would be near impossible for humans to discern.
A game-changing moment arrived in 2017 with the publication of the "Attention is all you need" paper by former Google researchers (https://arxiv.org/abs/1706.03762). Prior to this, Convolutional and Recurrent Neural Networks (CNNs and RNNs) were the most prominent AI models, playing crucial roles across industries and use cases. The paper introduced a groundbreaking concept—the Transformer—a new, simplified network architecture that completely departs from recurrence and convolutions, instead harnessing the power of attention mechanisms.
At its core, a Transformer is a neural network that derives context and meaning by establishing relationships within sequential data. Unlike traditional RNNs, which process data sequentially and struggle with lengthy sequences, Transformers perceive the entire input sequence simultaneously. RNNs also face challenges in maintaining relationship awareness and often suffer from forgetfulness. Additionally, their sequential nature prevents them from fully leveraging modern high-speed computing engines such as TPUs and GPUs. Conversely, CNNs are easier to parallelize, making them popular in NLP applications. However, they tend to lose effectiveness when confronted with long sentences.
The Transformers architecture enables computing parallelization, which in itself unlocks two significant benefits: the ability to process and train on vast amounts of data, and faster training and processing times. In essence, models based on the Transformer architecture can handle larger volumes of data and achieve faster results.
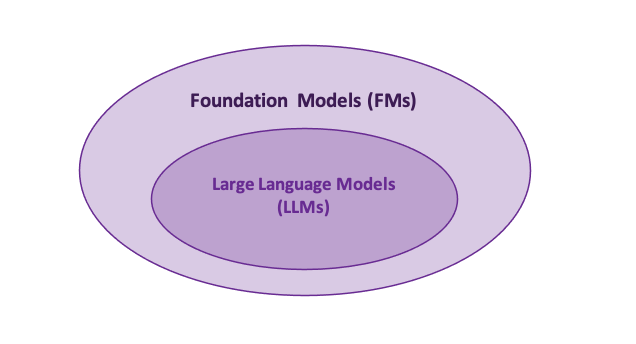
Foundation Models (FMs) and Large Language Models (LLMs)
Suddenly, neural networks made an unprecedented leap from handling millions of parameters to billions. Google's PaLM transformer-based LLM, introduced in April 2022, boasts an astonishing 540 billion parameters. Another notable example is BERT, created by Google in 2018, with 340 million parameters.
The advent of Transformers inspired researchers to create immensely large neural networks, trained on massive unlabeled datasets using unsupervised learning techniques. These models were known as Foundation Models, a concept coined by Stanford researchers in their paper titled "On the Opportunities and Risks of Foundation Models" (https://arxiv.org/abs/2108.07258).
Foundation Models possess the following characteristics:
- Pre-trained using unsupervised learning or self-supervised learning.
- Generalized, intended to serve as a foundation or basis rather than being tailored to specific tasks or goals.
- Adaptable through prompting.
- Deep neural networks, primarily utilizing the Transformer architecture but not limited to it.
- Trained on multimodal data, incorporating a mix of text, images, videos, and audio.
Large Language Models (LLMs), on the other hand, are Foundation Models trained on extensive unlabeled text datasets. They learn context and meaning by tracking relationships in sequential data and, due to their Transformer architecture, typically consists of billions of parameters.
 Parameters – The Key to Sophistication
Parameters – The Key to Sophistication
Neural networks remain the cornerstone of AI, and a significant breakthrough occurred when it became possible to create models with billions or even trillions of parameters (e.g. GPT-4 is a trillion-parameter model https://en.wikipedia.org/wiki/GPT-4).
Essentially, the number of parameters in a model determines its power and accuracy. Parameters are values that control the behavior of the neural network, dictating how it processes input data and generates output. Neural networks are essentially mathematical algorithms, and during the training phase, these parameters are adjusted to learn patterns in the data and make predictions. When data is fed into the neural network, the algorithm produces output based on the values of these parameters.
Key Takeaways
- Generative AI has emerged as the most powerful and user-friendly AI model to date. The AI revolution gained significant momentum with Google's Transformer model architecture, which paved the way for the development of more advanced AI models that are profoundly disrupting every field they are applied to.
- Training a Large Language Model is a complex and resource-intensive endeavor, though not necessarily prohibitive for large corporations. Pre-trained models and integrated offerings in public cloud services will play a crucial role in proliferating Generative AI in business settings and AI-powered enterprises. Additionally, the capability to fine-tune models will be essential for those who aim to stay ahead in the game.
About Encora
Fast-growing tech companies partner with Encora to outsource product development and drive growth. Contact us to learn more about our software engineering capabilities.
About the Author
Rodrigo Vargas is a leader of Encora’s Data Science & Engineering Technology Practice. In addition, he oversees project delivery for the Central & South America division, guaranteeing customer satisfaction through best-in-class services.
Rodrigo has 20 years of experience in the IT industry, going from a passionate Software Engineer to an even more passionate, insightful, and disruptive leader in areas that span different technology specializations that includes Enterprise Software Architecture, Digital Transformation, Systems Modernization, Product Development, IoT, AI/ML, and Data Science, among others.
Passionate about data, human behavior and how technology can help make our lives better, Rodrigo’s focus is on finding innovative, disruptive ways to better understand how data democratization can deliver best-in-class services that drive better decision making. Rodrigo has a BS degree in Computer Science from Tecnológico de Costa Rica and a MSc in Control Engineering from Tecnológico de Monterrey.

