
How often do you want to deploy to production? Weekly, daily, maybe as soon as possible? In this article, we are going to discuss an approach to deliver fast to production by using feature environments and a release process.
Feature Environments
A feature environment is a feature branch deployed in an ephemeral environment, which enables automated tests and QA to test that feature in isolation, before deploying to production [1]. It's a separate staging environment for each feature branch, allowing fast delivery of the features.
Figure 1 demonstrates the concept and process of feature environments.
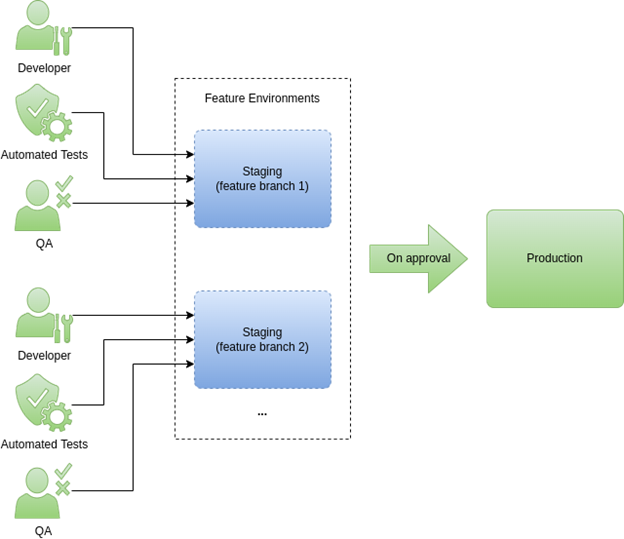
Figure 1 – Feature Environments
Let's propose an example to demonstrate in more detail how to use feature environments. Suppose we are developing a system called Example. This system has a mobile app and an API (hosted on api.example.com), which in turn uses a database (example_db) and a cache. The production environment is represented in Figure 2.
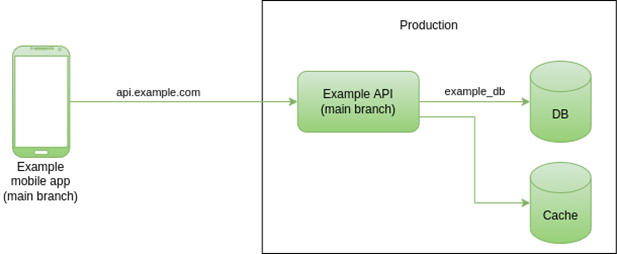
Figure 2 – Architecture of the Example system in production
We are going to discuss how to apply feature environments for the Example API. The mobile app follows a similar process, but with feature branch builds, i.e., each feature branch generates a different build.
Also, it’s important to keep in mind that the mobile app should be able to be configured to connect to any API address. This can be achieved by enabling a testing mode that would allow us to select or type the environment to connect. The same rule should apply to other clients (e.g., web app), if any.
Given that, let’s discuss some points before checking the architecture of feature environments for this Example system:
- Main branch: The main branch should represent a stable code that is already or is about to be deployed to production. Feature environments should represent the main branch plus an increment
- URLs : Each feature environment should be hosted in a different URL. So, we need to create a convention for URLs. For the Example API, the feature environment addresses should always be <feature environment name>-staging.example.com
- Feature environment name: The name of a feature environment should be the related feature branch name in lower case and with characters that a URL accepts. Example: if your feature branch is EXMP-1 (e.g., the ticket identifier), the feature environment name should be exmp-1. Prefer shorter names, so it will be easier to find the related resources and URLs
- Isolated resources: Each feature environment should have its own isolated resources. We can use ephemeral resources or even create specific resources containing the feature environment name as part of their names. For example, suppose for the cache it’s cheap to spin up an ephemeral resource and for the database it’s costly. So, for the feature environment exmp-1, we can use a completely separated cache server, but we can share the main database server by creating databases with the feature environment name (e.g., for expm-1, the database name would be exmp-1-example_db)
- API configurations: As the API should use isolated resources in each feature environment, each of them will have different URLs and/or names. So, the configuration should be flexible enough to support that. We can use configurations driven by environment variables, so it should be easy to change them in both remote servers and in the developer’s machine
- Main staging: Although feature environments are staging environments, we still need a stable one – the main staging. We may need to do specific tests against it or even if there is no feature environment, we need at least one non-production environment. Moreover, in more complex scenarios involving more APIs, we may have dependencies among them, and each API deployed in a feature environment should connect to dependencies deployed in the main staging. Considering all these points, Figure 3 depicts the architecture of feature environments for the Example API.
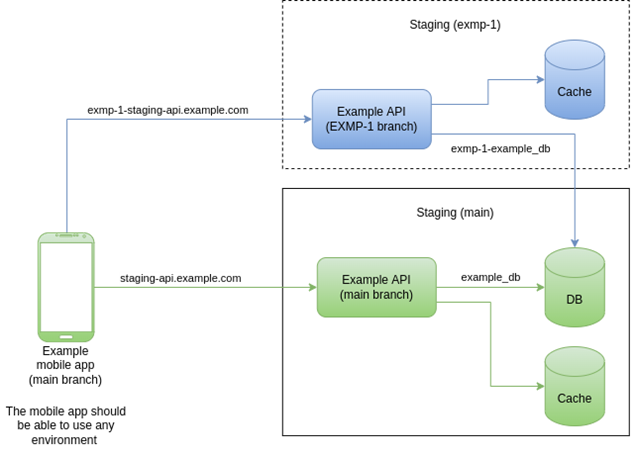
Figure 3 – Architecture of feature environments for the Example API
In Figure 3, we represented only one feature environment and the main staging. However, there can be N feature environments at the same time. Also, note that the feature environments attach to the main staging because they share the same database server. As we already mentioned, there can be other dependencies with the main staging in more complex scenarios.
How to manage these N feature environments? There should be a release process to dictate when a feature environment should be created or destroyed. This is going to be covered in the next section.
Release Process
Once we understood the basis of feature environments and checked the Example API, we can propose a release process that demonstrates how to deliver fast to production. This process contains the main aspects that leverage feature environments and fast delivery, but it’s important to mention that it can be simplified, optimized, or even changed in some parts, depending on your project needs.
To explain this process, we are going to use the Example API and a task called EXMP-1 that needs to be implemented and deployed to production. Let’s start with the process from that task being “ready to be implemented” to it becoming “ready for production”. Figure 4 describes all required steps to accomplish this.
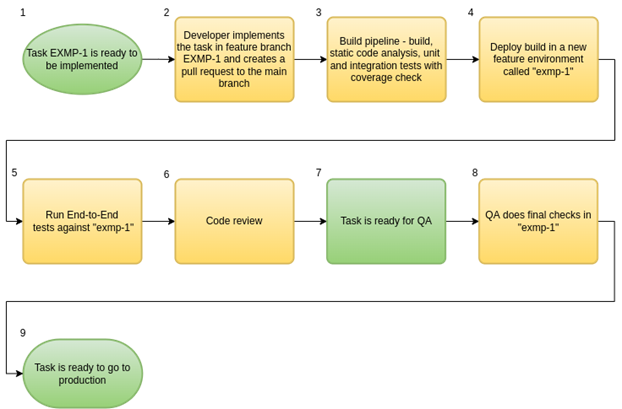
Figure 4 – Release process – part 1
Steps 3 and 5 are crucial points in this process: automated tests. They are especially important to ensure the new feature/change is working as designed and other features are still working (regression tests). In step 3, unit tests should cover methods in isolation, whereas integration tests should cover so many different ramifications of the code. We also need to enforce a high percentage of code coverage to ensure the developers created enough tests. In step 5, automated End-to-End tests run against the feature environment to ensure the entire flow is working.
Code review is done in step 6 and then the task is ready for QA. It could also be done in parallel with step 3, but we prefer it after the tests, so the code under review is stable and potentially ready to go to production.
QA comes into play to do par final checks (step 8), which can include smoke tests with the clients of the API, some exploratory tests, etc.
Any change in the feature branch (due to code review, bug, test failing, product request, back merge etc.) makes the task return to step 3. This is important to ensure the changes implemented are stable.
When EXMP-1 is approved to go to production, it follows the process described in Figure 5, until it is done.
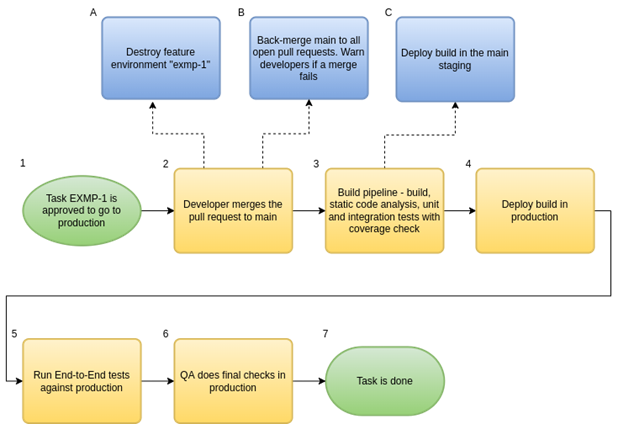
Figure 5 – Release process – part 2
The production deployment flow is represented in yellow and green. However, some steps are represented in blue, and they run in parallel without blocking the main flow. They are important for the feature environments, but not for the production deployment:
- Step A includes all required actions to remove feature environment resources: deployment, database, cache instances, DNS addresses, etc. It is not represented here, but this step should also run if a pull request is closed without merging
- Step B is important to keep all other feature environments up-to-date with the main branch. If the automatic back merge fails, the developer responsible for the task will need to back merge main to their feature branch manually
Step C is important to keep the main staging updated with production
Even with step B, we don’t recommend promoting the code from the feature branch build directly to production, because the main branch must be the sole source of truth. Also, a pull request should only be merged if it’s up to date with the main branch, otherwise, there is the risk of losing changes.
Lastly, if automated tests or QA finds a critical bug in production, it’s important to have other practices already implemented to either revert the deployment or disable the new feature:
- Rollback process: There should be a rollback process (even manual) to roll back a production deployment. Blue-Green deployments can also help here
- Feature flags: As a production deployment rollback can be a bit drastic and dangerous (mainly if it involves schema or data changes), feature flags can help if we just need to disable the new feature that has just been deployed
- Monitoring and observability: We should be able to know quickly if something is not right in production and react fast.
Key Points to Consider
Before adopting the release process, we have seen in the last section, we should discuss some pros and cons.
Pros:
- Product management and/or development team can select when features go to production: With this process, it’s not necessary to wait for a batch of changes to be stable before deploying to production. These speeds up the delivery to production a lot. We can have production releases every time a new feature/fix is ready
- Encourage short release cycles: Every time a pull request is merged into main, all other open pull requests are automatically updated and there can be conflicts. As solving code conflicts (developers) and retesting features (QA) are tasks they would like to avoid, they will compete (in a satisfactory manner) to have their pull requests merged into main as soon as possible. This indirectly encourages small and frequent deployments to production
- Test code in isolation: This strategy avoids postponing an entire release as commonly happens when QA needs to test a new feature/fix that is intermingled with other untested code. Thus, if a bug is found, an entire release can be postponed and it may be difficult to say which feature/fix caused that bug.
- Easy to do a hotfix: A hotfix doesn't need to override the staging environment or block any other development work [3]. Just create a new feature environment with the required changes.
- Easy to debug: Code in a feature environment is the main branch plus an increment, so it’s easier to troubleshoot.
- Easy to do experiments: We can create a feature environment with changes for the product team to evaluate.
- Easy to revert changes: We just need to close the pull request and the feature environment will be destroyed.
Cons:
- Complex to implement: The entire infrastructure can take a while to be implemented. However, infrastructure automation can help to accomplish this. Examples of tools and techniques include Infrastructure as Code, GitOps, Kubernetes and GitHub Actions.
- Costs: With more environments, more costs. Again, another point that forces the team to try to merge their pull requests as soon as possible. Also, note that if the feature environments are not properly managed and supervised, you may end up increasing your costs with infrastructure even more.
- Requires more communication and planning: In order to make this process fluid, tasks should be as small and as independent as possible. Also, the team needs to plan better the order of implementation and deployment of the tasks.
- Many different staging environments: QA is constantly changing the target address in their tests, and this can be a bit confusing, at least in the beginning.
- Practice: This process requires a bit of practice until the team gets used to it.
Conclusion
In this article we presented an approach to apply feature environments to deploy faster to production with short release cycles. You can now evaluate if this approach can be applied to your project and also make some adjustments to it, if necessary.
References
[1] LÜDEMANN, C. Feature Environments In All Environments – A Guide To Faster Delivery. 2018. https://christianlydemann.com/feature-branches-in-all-environments-a-guide-to-test-once-and-deploy/
[2] LÜDEMANN, C. Implementing Continuous Delivery Through Five Steps. 2018. https://christianlydemann.com/implementing-continuous-delivery-through-five-steps/
[3] SURENDRAN, A. What are On-Demand Feature Environments? 2020. https://medium.com/techbeatly/what-are-on-demand-feature-environments-982eaa96fdd5
Acknowledgement
This article was written by João Sávio Ceregatti Longo, Principal, Systems Architect and Tech Lead. Thanks to André Scandaroli, Isac Sacchi Souza, João Caleffi and Kathleen McCabe for reviews and insights.
Further Reading
The importance and value of Feature Flag Management
Architectural Design Patterns: Infrastructure as Code
Test Automation as a Zero Downtime Deployment Supporting Technique
Zero Downtime Deployment Techniques - Blue-Green Deployments
GitOps Patterns (inside and outside Kubernetes)
About Encora
Fast-growing tech companies partner with Encora to outsource product development and drive growth. Contact us to learn more about our software engineering capabilities.


