At the heart of any deep learning system, there is a significant effort in building it.
In the last few years, scaling deep learning models has become one of the most promising paths for artificial intelligence, specifically for large AI laboratories like OpenAI and DeepMind.
To have a clear feeling of this trend, let us examine recent large language models (LLMs) such as BERT and GPT-3. Let’s start with BERT or Bidirectional Encoder Representations from Transformers. BERT was introduced in 2018 by Jacob Devlin and his colleagues at Google. Large Language Models such as BERT are responsible for the current revolution of Natural Language Processing (NLP). BERT is a self-supervised learning system that learns representations from enormous text datasets without any kind of annotation. Using representation from BERT, one can solve many supervised NLP tasks like translation and Named Entity Recognition, with a fraction of annotated data. In other words, BERT representations eliminate the necessity of having large annotated datasets to solve NLP tasks.
One of the most impactful revolutions of LLMs like BERT was in the area of Search. Engines like Google Search, Microsoft Bing, or DuckDuck Go, share a common problem — they need to understand language. After all, if one can clearly understand what people are looking for when they type queries on web search engines, an essential part of the problem is already solved.
As a quick example, consider the following query that one might type on Google search.
“2019 brazil traveler to usa need a visa.”
In order to understand a query like this one, the search engine needs to be clever enough to consider some nuances. First, “brazil” is a country, and it does not matter if the user did not capitalize it, he or she is still hoping to get useful results. The same can be said to the word “usa”. Moreover, the word “to” in the sentence is critical. It describes the real intent of the person asking the question. After all, the question is about traveling from Brazil TO the US, not the other way around. To understand such small and important nuances of language, modern search engines rely on LLMs such as BERT. Nowadays, Google uses BERT representation in nearly every English query it receives.
However, training systems like BERT is no trivial task. Besides the algorithmic innovations behind it, one great imposition is scalability. To have an idea, the large version of BERT released by Google has 340 Million parameters and requires 16 Cloud TPUs (64 TPU chips total) for training the system for four days. To put this information in terms of resources, the approximate cost of training BERT using Google’s infrastructure with Cloud TPUs is $7,000.

One Cloud TPU (v2–8) can deliver up to 180 teraflops and includes 64 GB of high-bandwidth memory. The colorful cables link multiple TPU devices together over a custom 2-D mesh network to form Cloud TPU Pods. These accelerators are programmed via TensorFlow and are widely available today on Google Cloud Platform.
Since BERT, larger language models such as GPT-3 and most recently Megatron-Turing NLG have been developed. The GPT-3 architecture contains 96 layers and 175 billion parameters. The estimated cost to train GPT-3, ranges from $5 to $12 million. Megatron-Turing Natural Language Generation from Microsoft and NVIDIA has mind-boggling 530 billion parameters.
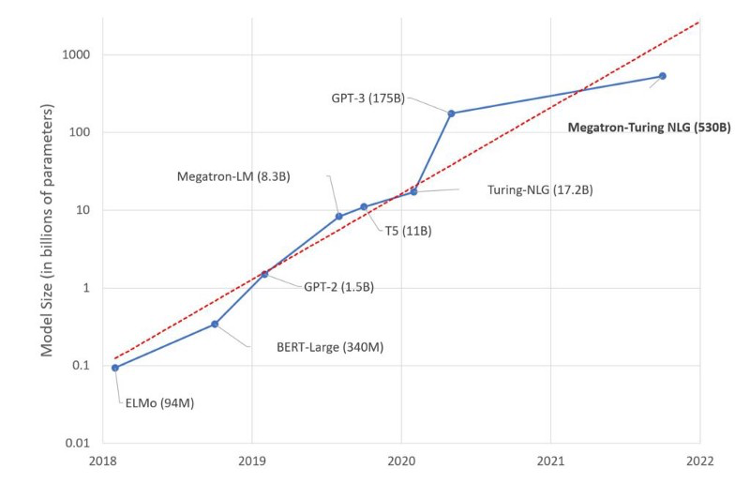
Source Image: Microsoft Research
This trend of scaling deep learning models is not particular to NLP applications. A similar pattern also happened in Computer vision a few years ago.
As a result, if one is thinking of using state-of-the-art deep learning systems to solve perceptual problems like Vision, NLP, or Speech, chances are that one is going to deal with one of these large models that require distributed training skills for training or fine-tuning the model to a particular task.
Approaches to Scaling Deep Learning models
There are two main paradigms to distributed training of deep learning models: Data parallelism and Model parallelism. Data parallelism is by far the easiest and most popular among the two. High-performance deep learning frameworks such as PyTorch implement both approaches, but strongly recommend users apply data parallelism instead of model parallelism when possible.
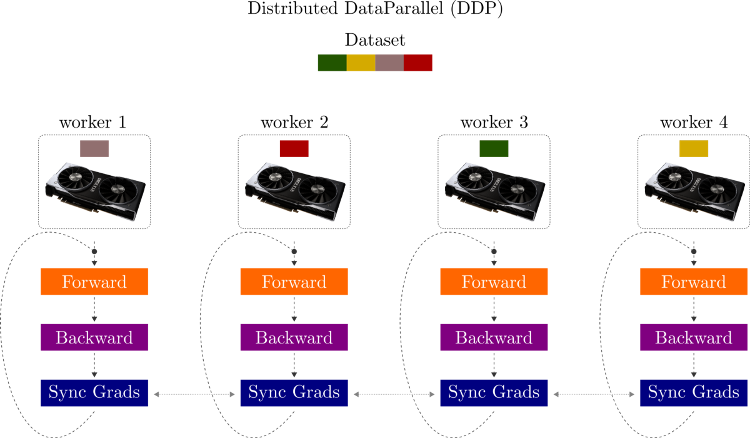
In Data parallelism, the data is divided into separate subsets, where the number of subsets equals the number of available worker nodes. We can think of a worker node as an independent process with its own memory and Python interpreter. Each worker receives its subset of the data and a copy of the original model.
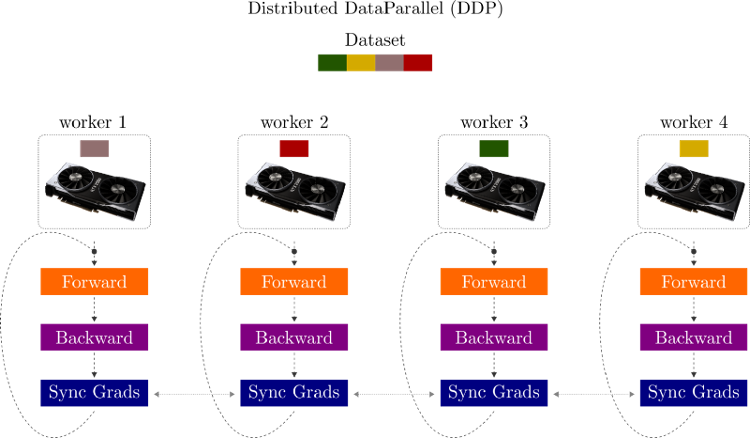
Notice that each worker needs to have enough memory to load the entire model into memory.
The training process works as follows, each worker:
- Generates a batch of examples from its subset
- Forwards the data through its local copy of the model
- Computes the errors between predictions and labels
- Updates the parameters of its own model
- Communicate the local changes to the other nodes
As for step 5, from time to time, workers need to synchronize gradients among themselves so that each node can update its local copy of the model based on the changes from its fellow workers. This process is usually done once per batch and performs gradient synchronization across all processes to ensure model consistency among workers.
Data parallelism is implemented on the DDP (Distributed Data-Parallel) package in PyTorch. DDP is a single-program multiple-data training paradigm. It is the recommended approach for distributed training in PyTorch because it can extract more parallelism than other Data parallelism approaches such as DataParallel.
Note that since DDP implements multi-process parallelism (each worker is a process), there is no GIL contention because each process has its own Python interpreter. Moreover, the package efficiently takes care of synchronizing gradients, so one does not need to be concerned about that step.
Distributed Data-Parallel is very useful for most situations when training deep learning models. However, there are some cases in which the Data parallelism paradigm does not fit quite well.
One of the implicit assumptions of Data parallelism is that the data is the most memory-heavy component to deal with. From this perspective, it is reasonable to think that we should split the data into smaller subsets and process them separately, as Data parallelism suggests. However, what if the model (not the data) is the most memory-expensive component? In this situation, the paradigm we have discussed so far would not work because, in Data parallelism, the same model is replicated across each worker. In other words, each worker needs to be able to load the entire model in memory.
That is where the other approach to distributed training, Model parallelism, makes itself valuable. In Model parallelism, instead of splitting the training data into subsets for each worker, the workers will now have access to the entire training data. However, rather than replicating the entire model at each worker, a single machine learning model will be split into many workers. Specifically, the layers of a deep learning model are split across different workers. For example, if a model contains 8 layers when using DDP, each GPU will have a replica of each of these 8 layers, whereas when using Model parallelism on, say, two GPUs, each GPU could host 4 layers.
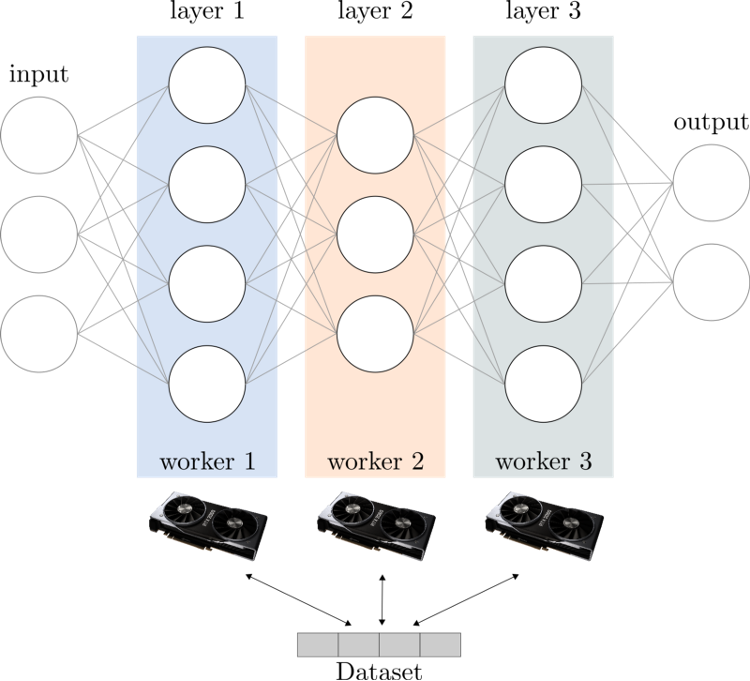
As you can see, in this paradigm, a single worker operates only on a part of the model (a subset of the layers). Hence, with the right synchronization, a collection of workers will be able to train a larger model. Frameworks like PyTorch, Tensorflow, and Chainer offer the strategy of Model parallelism. The general idea is to flag specific layers with a corresponding GPU identifier. Then, during training, the layers that were flagged with a GPU id, will be loaded and executed by that device.
Model parallelism is especially useful for situations where large mini-batches or high-resolution is required or in cases where the model is too large to fit on a single GPU.
In addition, for extremely large models, it is common to be entangled in a trade-off between extra communication (which slows the training process) or extra memory usage (which increases costs with memory and computing infrastructure).
For situations alike, advanced distributed training techniques such as the Fully Sharded Data Parallel (FSDP) arise as suitable candidates. As discussed, regular data parallel implementations such as DDP, require a redundant copy of the model on each worker. This copy is necessary so that each worker can perform a local update step with minimal communication among worker nodes.
On the other hand, model parallel techniques require extra communications to move activations among GPUs. Seeking a middle ground, FSDP reduces the trade-off between communication and memory by sharding model parameters, gradients, and the optimizer stages across GPUs. At the same time, it decomposes communications among worker nodes by performing smart overlapping of operations with the forward and backward methods.
Implemented in PyTorch in the FairScale library, FSDP is a data parallel algorithm that allows larger models to be trained using a small number of GPUs.
The core idea of FSDP is to avoid the redundancy of standard data-parallel techniques by applying a process called full parameter sharding. This process allows a worker node only to keep a subset of the model parameters, gradients, and optimizers needed for local computation (instead of the full model).
Since only a shard of the model is present on each worker node (instead of the full model), each worker needs to gather the missing shards from the other models to perform local forward and backward passes. After that, the local gradients are combined and sharded across all the worker nodes.
In short, we can view FSDP as an improved DDP since it reduces the memory footprint by avoiding copies of the same model on each worker. You can read more about FSDP on this blog post by Meta Research.
Key Takeaways
Deep learning models have been revolutionizing many areas of industry and science, mainly the ones that deal with perception problems like language, computer vision, and speech.
Nowadays, we can take advantage of large models, trained on large datasets using expensive parallel hardware, to solve many tasks of our day-to-day lives. However, training these models is not trivial. On the contrary, there are quite complex parallel training strategies with the power of solving tasks that would require years of serial computing, in a matter of days.
In general, if a model is small enough to fit in a single GPU, the best option is to use the Data parallelism distributed strategy. With just a few lines of code, one can split the work among different nodes, where each worker has its own memory address space and GPU. For situations where the model does not fit entirely in a single GPU, we can split layers of it across different GPUs, that is Model parallelism and is the best strategy to train very large deep learning models.
Acknowledgement
This piece was written by Thalles Silva, Innovation Expert at Encora’s Data Science & Engineering Technology Practices group. Thanks to João Caleffi and Kathleen McCabe for reviews and insights.

About Encora
Fast-growing tech companies partner with Encora to outsource product development and drive growth. Contact us to learn more about our software engineering capabilities.
Contact us