Cloud data warehouses are very useful because they allow companies to store, manage, and analyze large amounts of structured and semi-structured data by using the power of cloud computing. Multiple companies offer solutions that allow us to have our data warehouses, like Google, AWS, Oracle, and Microsoft. But there’s one that was listed as #2 on Forbes magazine’s Cloud 100 list and was ranked #1 on LinkedIn’s U.S. list of Top Startups a few years ago, and the name of this technology is Snowflake.
In this article, we will discuss some aspects that you should know before developing a data warehouse. This may help you decide if Snowflake fits you and your requirements best. We’re going to cover 3 main topics that are important to know before developing a data warehouse:
- Best Practices
- Architecture
- Query Performance
How Does Snowflake Help with Best Practices?
Foremost, we should consider some very important things as developers that help us detect and fix errors, and make code simpler, more readable, and easier to maintain, and this could be applied to any other Structured Query Language (SQL) engine.
Uppercase and Lowercase Objects
When writing SQL code, many developers choose to write the SQL objects with upper case, this doesn’t affect the efficiency of the engine at all, but it makes the code more maintainable because if an external person wants to read the code, it is easier to understand what is happening. In the case of developers who don’t use the caps lock button, Snowflake automatically converts objects’ names to upper case. When we want to use objects with mixed-case or lowercase letters, Snowflake allows us to call those objects by enclosing them in quotes. It is worth mentioning that this must be considered when creating our objects since some tools usually don’t accept special characters.
Object Names
Creating permanent and temporary tables in a database is a practice that is common when you’re designing a data warehouse. Temporary tables are session based and they are not bound by uniqueness requirements, that’s why creating a temporary table with the same name as another table is not a good practice to have.
Roles and Access
Snowflake allows users with certain roles to create specific types of database objects while restricting the ability of other users or roles to create those same objects. One example is the SYSADMIN role, which creates databases and virtual data warehouses. Also, Snowflake’s Time Travel capabilities are useful to return the objects to their original state.
Things You Should Know About the Snowflake Architecture
Snowflake is an evolutionary modern data platform that solves the scalability problem and provides a SQL query engine with an innovative architecture designed and built for the cloud.
The Snowflake hybrid-model architecture is composed of three layers: the cloud services layer, the compute layer, and the data storage layer.
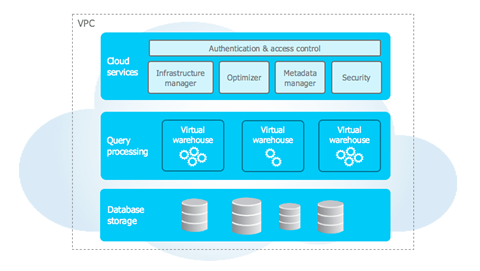
docs.snowflake.com
Snowflake works across multiple availability zones in each cloud provider region and holds the result cache, a cached copy of the executed query results, and all the metadata required for query optimization. This metadata is useful when you are trying to process the information with another big data tool like Apache Spark.
What is the Difference between Snowflake and Other Data Warehouses?
Snowflake allows you to create multiple virtual warehouses, this unique architecture allows for the separation of storage and computing, which means any virtual warehouse can access the same data as another, without any contention or impact on the performance of the other warehouses, since each virtual data warehouse operates independently. Another thing that’s important to mention is that it can be scaled up by resizing and adding more clusters at any time.
Query Performance and Optimization
Snowflake allows us to analyze the query performance using different ways like web UI’s history, QUERY_HISTORY profiling, and HASH () function. This helps in reducing costs by reducing processing time.
Web UI History
The web UI history is a web interface that allows us to view the main components of the queries processing plan. This helps in understanding the overall statistics of the query quickly.
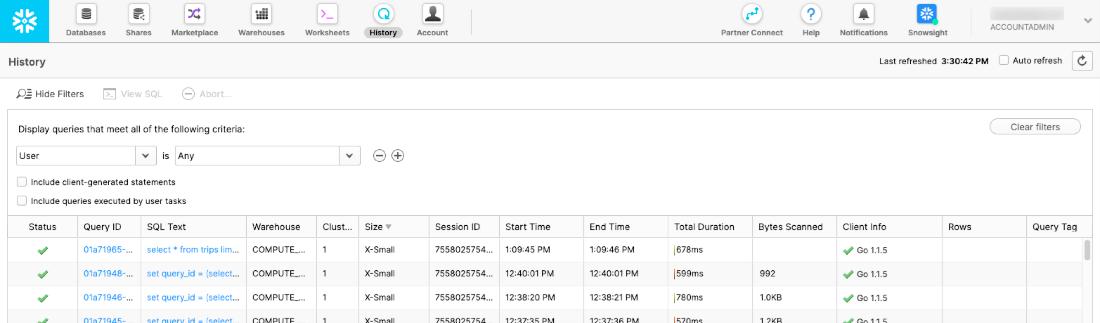
docs.snowflake.com
Query History
Snowflake automatically creates a table of each database where it stores the schemas of all the tables that exist, the function QUERY_HISTORY uses INFORMATION_SCHEMA that provides information about queries executed against a particular database.
As an example, here’s a query that allows us to review the queries run by the current user on the last day. This helps analyze and discover long-running queries that are run frequently and make changes to improve the performance.
USE ROLE ACCOUNTADMIN;
USE DATABASE ;
SELECT *
FROM TABLE(INFORMATION_SCHEMA.QUERY_HISTORY(
dateadd('days', -1, current_timestamp()),
current_timestamp()))
ORDER BY TOTAL_ELAPSED_TIME DESC;
Hash
This is not a cryptographic hash function. This function is a utility that returns information, such as descriptions of queries. For example, you may want to return the queries executed for a particular database, in order of frequency and average compilation time. In addition to the average compilation time, the average execution time is also included:
USE ROLE ACCOUNTADMIN;
USE DATABASE < database name >;
SELECT HASH(query_text), QUERY_TEXT, COUNT(*),
AVG(compilation_time), AVG(execution_time)
FROM TABLE(INFORMATION_SCHEMA.QUERY_HISTORY(dateadd('days', -1,
current_timestamp()),current_timestamp() ) )
GROUP BY HASH(query_text), QUERY_TEXT
ORDER BY COUNT(*) DESC, AVG(compilation_time) DESC ;
With this, we can improve the efficiency of the query compilation times and save on operational costs.
Conclusion
Choosing a platform for developing a data warehouse is not an easy thing, there are a lot of options in the market nowadays and each platform has different functionalities that you can take advantage of depending on the way you work with data. Snowflake is a good option given its friendly user interface, clean code, and optimization capabilities.

About Encora
Fast-growing tech companies partner with Encora to outsource product development and drive growth. Contact us to learn more about our software engineering capabilities.

