Data has taken center stage in the digital era, emphasizing data analytics and database management. Managing and processing large datasets pose formidable challenges. However, the quest for valuable insights has led to the development of data-driven technologies and tools, with Snowflake being a standout example.
Snowflake is a cloud-based data warehousing platform that has gained recognition for its remarkable attributes, such as efficiency, scalability, and performance optimization. A standout feature of Snowflake is its suite of estimation functions, facilitating swift insights into data characteristics without requiring exhaustive processing. When dealing with massive datasets, these functions are invaluable, addressing situations where precise calculations might otherwise prove computationally or memory-intensive, costly, and time-consuming.
The Growing Data Deluge and the Need for Estimation Functions
The world has witnessed an unprecedented surge in data generation in recent years. From e-commerce transactions and social media interactions to IoT devices and sensor data, information pours in from all directions. This surge is attributed to several factors, including the proliferation of digital technologies, the Internet of Things (IoT), and the increasing adoption of cloud computing. Consequently, organizations grapple with colossal datasets that can be challenging and expensive to process.
This is where estimation functions come into play. They offer a strategic solution to efficiently handle massive datasets by providing approximate results with significantly reduced computational overhead. While traditional methods involve analyzing every data point, estimation functions offer a quicker and more resource-efficient way to gain insights from data. Snowflake has recognized the importance of estimation functions as a cloud data platform and seamlessly integrated them into its architecture.
The Role of Estimation Functions
Estimation functions offer a breakthrough by providing approximate results that are often "good enough" for many business use cases. For instance, in real-time analytics, where quick decisions are crucial, estimation can provide timely insights without time-consuming full-scale data analysis. Similarly, estimation functions can be a game-changer in scenarios such as trend analysis, market research, or anomaly detection, where trends or anomalies must be identified rapidly.
Imagine a large e-commerce platform analyzing user behavior to personalize product recommendations. Instead of analyzing the entire purchase history of every user, estimation functions can quickly identify trends and preferences, leading to more effective recommendations while saving computational resources.
How Snowflake Estimation Functions Work
Snowflake estimation functions utilize statistical sampling techniques to provide rapid and relatively accurate results. Instead of scanning the entire dataset, these functions operate on a fraction of the data, applying algorithms that extrapolate observed patterns to the complete dataset. This allows for quick estimations while maintaining a reasonable level of accuracy.
Benefits and Considerations
The benefits of Snowflake estimation functions are manifold. They include:
Performance Optimization: Estimation functions significantly enhance query performance by providing rapid insights without full-scale processing.
Resource Efficiency: Estimation functions reduce the strain on system resources, allowing for smoother and more efficient data analysis.
Cost Savings: With reduced processing requirements, you can achieve your analytical goals while optimizing costs associated with data processing.
It is crucial to understand that estimation functions provide an approximate result. Depending on the use case, one should balance considerations between performance, efficiency, cost, and accuracy.
Snowflake's Estimation Functions: A Brief Overview
Snowflake, known for its robust cloud data warehousing capabilities, offers a suite of estimation functions that empower organizations to process and analyze their data efficiently. Some of the notable estimation functions in Snowflake include:
Cardinality Estimation
Cardinality estimation functions are essential tools for understanding the uniqueness and distribution of values in a column. Cardinality refers to the number of distinct values in a column or a dataset. Snowflake provides the following cardinality estimation functions:
- APPROX_COUNT_DISTINCT: Uses HyperLogLog to return an approximation of the distinct cardinality of the input
- HLL: Alias for APPROX_COUNT_DISTINCT
- HLL_ACCUMULATE: Returns the HyperLogLog state at the end of aggregation.
- HLL_COMBINE: Combines (merges) input states into a single output state.
- HLL_ESTIMATE: Returns the cardinality estimate for the given HyperLogLog state.
- HLL_EXPORT: Converts input in BINARY format to OBJECT format.
- HLL_IMPORT: Converts input in OBJECT format to BINARY format.
Similarity Estimation
Similarity Estimation functions estimate the similarity between strings and documents. These functions can be very useful for various applications such as text analysis, data cleansing, and duplicate detection.
- APPROXIMATE_SIMILARITY: Returns an estimation of the similarity (Jaccard index) of inputs based on their MinHash states.
- APPROXIMATE_JACCARD_INDEX: Alias for APPROXIMATE_SIMILARITY
- MINHASH: Returns a MinHash state containing an array of size k constructed by applying k number of different hash functions to the input rows and keeping the minimum of each hash function.
- MINHASH_COMBINE: Combines input MinHash states into a single MinHash output state.
Frequency Estimation
Frequency estimation functions help you analyze the distribution of data values within a column. These functions provide insights into the occurrence and frequency of specific values, allowing you to understand the data's characteristics better.
- APPROX_TOP_K: Uses Space-Saving to return an approximation of the most frequent values in the input, along with their approximate frequencies.
- APPROX_TOP_K_ACCUMULATE: Returns the Space-Saving summary at the end of aggregation.
- APPROX_TOP_K_COMBINE: Combines (merges) input states into a single output state.
- APPROX_TOP_K_ESTIMATE: Returns the approximate most frequent values and their estimated frequency for the given Space-Saving state.
Percentile Estimation
Percentile estimation functions are used to calculate percentiles within a dataset. Percentiles are statistical measures that indicate the relative standing of a particular value within a dataset.
- APPROX_PERCENTILE: Returns an approximated value for the desired percentile.
- APPROX_PERCENTILE_ACCUMULATE: Returns the internal representation of the t-Digest state (as a JSON object) at the end of aggregation.
- APPROX_PERCENTILE_COMBINE: Combines (merges) percentile input states into a single output state.
- APPROX_PERCENTILE_ESTIMATE: Returns the desired approximated percentile value for the specified t-Digest state.
These functions are designed to balance accuracy and performance, making them invaluable tools for organizations dealing with massive datasets.
A Use Case in the Pharmacy Domain
To illustrate the practicality of Snowflake's estimation functions, let's consider a use case in the pharmacy domain. Imagine a national pharmacy chain with a vast database of prescription records. They need to quickly identify trends in medication prescriptions to optimize inventory management and gauge that they have adequate quantities of medications in stock.
Using Snowflake's estimation functions, the pharmacy can employ APPROX_COUNT_DISTINCT to approximate the number of unique medications prescribed within a specific timeframe. This allows them to monitor trends in medication usage without the computational overhead of counting every prescription individually.
Additionally, APPROX_TOPK can be used to identify the most prescribed medications, helping the pharmacy prioritize stock levels for these items. This ensures that they can meet demand efficiently, reducing the risk of running out of crucial medications.
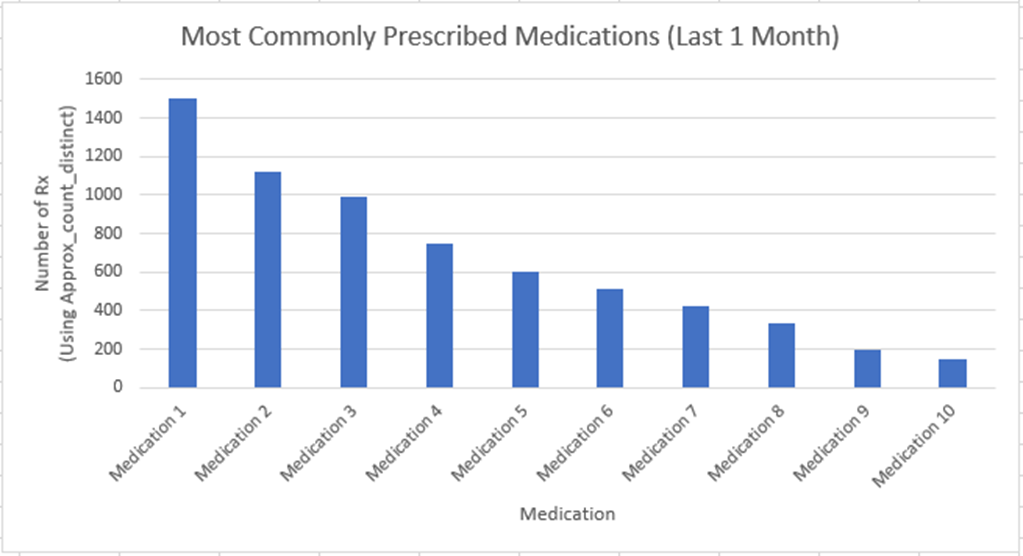
The Visual Effect
Looking at data alone is not always helpful unless it is presented in a meaningful data visualization. In the following visualization, we can see that "Medication 1" has been trending over the last month. Such visualizations help pharmacies gain a comprehensive understanding of both high-demand medications and the diversity of prescriptions over time. This insight ensures that they not only meet immediate demands but also prepare for future trends effectively, optimizing inventory management and customer satisfaction.
Encora’s Snowflake Practitioners Group
Encora's dedicated team of skilled and experienced practitioners in Snowflake has been working diligently over the years to develop innovative solutions to tackle a diverse range of business problems that require quick and efficient analytics. These solutions are designed to offer a more streamlined approach, instead of relying on complex and convoluted methods. Encora has been instrumental in helping its clients create reliable, scalable, and reusable processes by staying up to date with the latest advancements in Snowflake and incorporating them into data and analytics projects.
Key Takeaways
Data has become a crucial aspect of businesses and organizations in today's world. With an ever-increasing volume of data, organizations face challenges in terms of data management, processing, and analysis. This is where Snowflake's estimation functions come in as a powerful solution. They offer an efficient way to process data and provide approximate results, allowing organizations to make timely decisions, allocate resources optimally, and extract valuable insights from their data. The results provided by these functions are not only accurate but also faster to generate, making them crucial for organizations seeking a competitive edge.
Moreover, Snowflake's estimation functions are designed to work with large datasets, making them ideal for organizations dealing with vast amounts of data. These functions provide organizations with the ability to estimate results without having to process the entire dataset, thereby saving time and resources.
In conclusion, Snowflake's estimation functions are a game-changer in the world of data analytics and decision-making. They offer an effective and efficient solution to the challenges posed by the growing volume of data, making them crucial for organizations seeking to stay ahead of the competition.

About Encora
Fast-growing tech companies partner with Encora to outsource product development and drive growth. Contact us to learn more about our software engineering capabilities.

