Incident Management in a public Cloud environment demands a level of orchestration spanning teams across customers, development partners, and Cloud providers. This article describes critical actions for IT managers and stakeholders that, in our experience, enable a successful experience in navigating these types of incidents.
Explore Your Options Beforehand
As many customers choose the Pay-As-You-Go (PAYG) model of public Cloud providers like Microsoft Azure or Amazon Web Services because of the attractive savings it offers, they tend to mistakenly assume that there is no real support available to them when they are not paying the big bucks of Enterprise Agreements for this item, which is fortunately a false assumption.
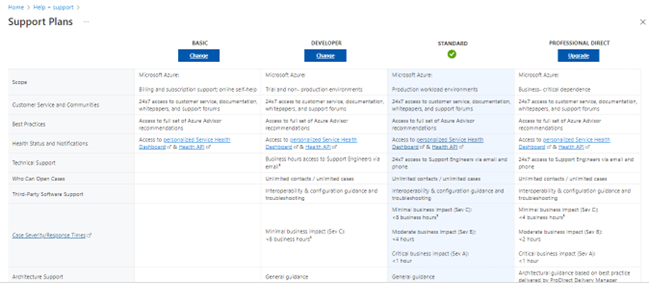
As seen in the above image, the Standard support plan provided for non-critical production workloads in PAYG subscriptions in Microsoft Azure, for just $100 per month, shares pretty much the same level of resource accessibility and availability as the more sophisticated and expensive “professional direct”, even to the point of 24x7 support available by phone or email.
So, it is crucial that you are aware of the options made available to you by the public Cloud provider and have a plan ready on how to use them when the time comes to help resolve an incident.
Engage the Cloud Provider Early in the Process
Another common mistake is wasting too much time trying to do it alone. In our experience, it is worth investing enough time in diagnosing the issue and testing hypotheses for solutions. Although, if you find the team is unclear after a prudent time, do not hesitate to open a support ticket with the Cloud provider.
Even if the given issue falls outside their scope, the support teams are there to help you succeed with the provider’s platform. They even have some roles labeled as Customer Success roles that only focus on solving the issue. So, they can quickly point you in the right direction, either by accessing key service logs and configurations within the platform to make confirmations, providing pointers to best practices regarding specific topics, or even assisting you to connect with other teams that could get engaged to better support you. The next point will discuss this further.
Beware of Gray Areas Inherent to Cloud Technology and Resources Expertise
IT teams within customers and software service providers are usually split into broad areas of responsibility such as development/delivery, development operations, quality assurance, and data engineering. So, we’ve all been there. A typical question when an issue arises is: Is it the code’s fault, or is it the infrastructure’s fault?
Sometimes the answer is more complicated than we may expect. Especially when dealing with complex issues, the lines between infrastructure and code can be blurry. It is quite relevant to acknowledge this. In simple terms, the Cloud environment provides dozens of configurations available for its platform services. These settings can be defined in the development environment by the developer, at the management portal or console by the operations engineer, or at the development operations side by either of them. Furthermore, and here’s where the caveat lies, specific pieces of code need to be structured in certain ways so they can interact properly with the configurations made in the underlying Cloud infrastructure. Sometimes the infrastructure configuration is performed from within the code itself.
So, with this in mind, let’s get back to our question: Is it the code or the infrastructure? Whom do we assign for diagnosis? The developer who spends 80% of their time coding and away from the infrastructure, or the DevOps Engineer who spends 80% of theirs dealing with the infrastructure and away from the code.
Experience tells us that it is useful to get started by default with the development end; however, if you have trustworthy leadership here, trust them when they indicate that something is not originating from within the code. At this point, involve the DevOps Engineer so they can work together to find the source as a team instead of having them act out isolated from one another.

Keep a Log of Incidents, Solutions, and Lessons Learned
It seems outdated. Nevertheless, it can save you and your team significant pain and time. Even though we aim to get issues resolved from the root and take action to prevent their reoccurrence, experience tells us that they do reoccur. Either because the root cause analysis failed partially or completely, because some external or out-of-control factor was triggered, or even due to human error or omission.
If you don’t invest in keeping a log of the occurred incidents, what specifically got the issue resolved, why it did, and what you learned from the experience, you will pay it all over again a few months down the road when the same issue or a pretty similar one occurs and no one can describe exactly which action resolved the issue in the past or if it was one configuration or another.
Acknowledge the Complexity of the Support Model
We all understand that public Cloud providers offer a depth and breadth of services that are quite significant. As shown in the below image, which depicts the high-level categories of Microsoft Azure Services: Platform, Infrastructure, Data Centre, Security & Management, and Hybrid Cloud.
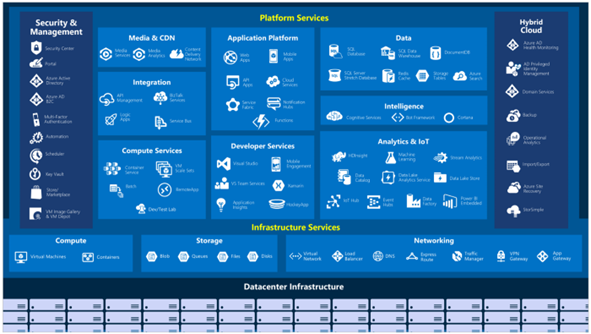
It may not be as obvious that such complexity is translated in many teams that provide support for these services. And it becomes clear once you engage with one of them. For example, a ticket for support with the Azure Service Fabric team can eventually get routed to different teams within the realm of the service (support team vs product team), or even to teams supporting other services that could be involved in the incident.
It is important to be aware of this reality and to be ready with the documentation and a description of where the case is, what has been done, and what still needs to be done. Generally, these teams do a decent job of transferring your incident among themselves, although, your team is the constant link from end-to-end, so both your IT team and the technology partner's IT team need to stay on top of their game and what is going on, even if they do not act actively in some points.
Putting it All Together
To successfully manage incidents in your public Cloud environments, it is important to understand beforehand the options that are available to you, engage the Cloud provider early in the process, stay aware of the technological, knowledge, and support delivery complexities inherent to the Cloud, and keep a record of the incidents over time. Most importantly, you must have a knowledgeable technology partner who is aware of these factors and can align with your teams and work together with you and the Cloud provider to orchestrate your path to success properly.
Key Takeaways
In this article, we explored the key factors for successfully handling workload incidents in a public Cloud environment. These include, but are not limited to the following:
- Explore the options available in your support model beforehand
- Leverage the Cloud provider to your advantage by engaging them early in the process
- Beware of the gray areas inherent to the complexity of Cloud technology
- Keep records of the incidents and the solutions over time for future reference
- Engage with a technology partner that has the capacity and resources to help you orchestrate
References
- About Migrating Workloads to the Cloud: https://www.encora.com/insights/maximizing-the-clouds-capabilities-cloud-native-development
- About Microsoft Azure Support Options: https://azure.microsoft.com/en-us/support
- About Amazon Web Services Support Options: https://docs.aws.amazon.com/awssupport/latest/user/aws-support-plans.html
- About Google Cloud Platform Support Options: https://cloud.google.com/support
About Encora
Fast-growing tech companies partner with Encora to outsource product development and drive growth. Contact us to learn more about our software engineering capabilities.

