
Clients are demanding more and more insights based on their data but, to achieve that, some foundational resources need to be in place to allow more advanced analysis and techniques. There are lots of tools and disciplines related to data handling in all aspects, both on premise and as cloud services, but we see that our clients value keeping a certain level of ownership over the entire process. In this context, Apache Airflow pops up as a good candidate for addressing this business need.
This article describes the stages of a Machine Learning (ML) or Data Science (DS) project and explores how a workflow solution, such as Apache Airflow, is worth considering for a good data pipeline.
Workflow frameworks for Data Engineering pipelines, Machine Learning and Data Science applications
There are many distinct solutions for pipeline and workflow management currently available on the market, with distinct levels of generality, complexity and adaptability. Among the many features and characteristics they might provide, it’s important to analyze how they support the main stages of a Machine Learning project — not only the final production workflows, but also how they support development and even a smooth transition from exploration all the way to deployment, production and maintenance.
Exploration phase
A workflow solution might not look like an essential part of the exploration phase, but there are two key aspects in which they can improve and support both data analysis and preliminary experiments:
- Common/generic approaches: Once ingested, data needs to be analyzed through a plethora of lenses — from simple statistics analysis to more complex distribution patterns, also including histograms over categorical variables, chart plotting/visualization and even training of simple models in order to check basic properties. All these steps can be automatically provided as a pipeline that not only automatically executes these processes, but also registers and stores the results.
- Seamless integration with the development phase: Once the first initial analysis has been completed, a more customized set of pre-processing approaches will be developed and experiments will be performed. It’s common, however, to either reuse experimental code (which is usually done without all steps required by actual development) or start them fully from scratch. However, if the experiments are already being executed from within a pipeline, slowly upgrading them on a containerized format might be beneficial — both conceptually (keeping different steps independent from each other) and by using structures such as Docker containers in a Kubernetes environment. In fact, since the testing environment can be also added as another workflow, tests can be performed and stored from a very early stage and become comparable with development-phase solutions, without forcing the reuse of exploratory code on the final version.

Example of a generic workflow for feature selection exploration
Development phase
The transition from Exploration to Development in Machine Learning projects is usually one of the most drastic and disruptive changes: By consolidating a proof of concept into actual code, many characteristics and features that could have been ignored in earlier steps must be addressed.
The three main areas to be tackled are non-functional requirements (such as security and logging), attendance to development standards (such as unit testing, coding patterns and data structures) and integration with the solution as a whole. In fact, it’s a good practice to not reuse any code from the exploration phase during development, since exploration code is usually unstable and doesn’t necessarily follow all the expected good practices.
Workflow solutions are very useful in the development phase for two main reasons:
- They allow actual development and testing to be highly interactive, with shorter cycles of coding and testing (which also includes the seamless integration described in the previous section, since most of the code developed earlier is already compatible with the development infrastructure);
- Incremental development: even though Exploration-phase code shouldn’t be used in the final version of a product, by using a workflow’s naturally segmented, modular approach it’s easier to implement and replace specific pieces of code as they are developed, especially once the interfaces are fixed. As explained in the previous step, other modules and tasks that were previously implemented can also be easily integrated in a workflow, avoiding both re-implementation and wasted time integrating different code solutions.
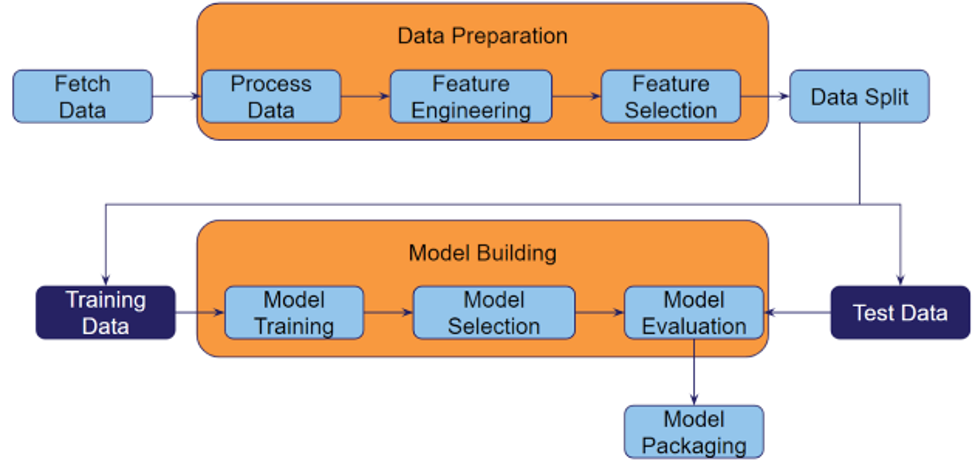
Example of a generic workflow for development
Deployment phase
Deployment is often overlooked during development of a Data Science or Machine Learning solution, but it’s not uncommon for solution deployment to take considerable time and effort — especially when data (or the very environment) is sensitive and highly protected. In these cases, deployment often requires manual configuration on premises, which then must be tested again.
Deployment frequently relies on other tools and platforms, such as REST APIs or Web Servers that must be exposed and are usually very distinct from the data solution. While the previous phases are more concerned with the actual application, during deployment other external sources of information and control will be considered, and these environments can be very heterogeneous. In fact, most of them will be outside the scope of the data application, which is why these connectors should be added to a workflow during this phase.
In a workflow-based solution, not only actual deployment and testing can be fully automated with little to no extra code involved, since all steps so far can be reused, but it can also be abstracted in a reusable workflow. Once a generic ‘model to production’ task has been implemented, it can be reused for different models and applications by simply replacing the tasks in the workflow that would generate the request model, for example.
Production and Maintenance phase
Finally, once all steps have been implemented and deployed, it’s time to maintain the production system . This includes tracking, logging, continuous training, continuous evaluation and, eventually, software updates.
At this stage, workflows are already a very common solution, since they allow processes to be clearly mapped, tracked and scheduled. The main advantage, in this case, is that all the previous steps would already have been implemented in a workflow format, avoiding rework and making it much easier to upgrade and retrofit solutions.
Once one robust workflow for continuous training and deployment has been developed, with all the necessary logging and tracking tools, the mere replacement of tasks can allow it to be updated, adjusted to new output formats, or even reused for completely different data solutions. Since each task is virtually independent from the others, interfaces are the only thing that must be kept and maintained from one workflow to another.
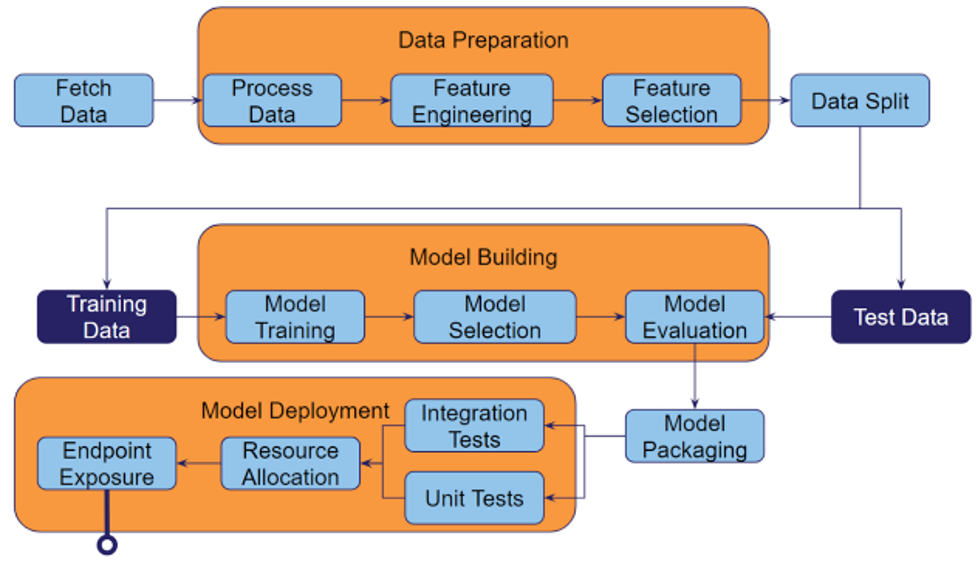
Example of a generic workflow for deployment and production
Workflow solutions: key characteristics
Other than supporting Machine Learning processes, a workflow solution can improve development and performance by providing integration with infrastructure. If such integration exists, performance and stability tests can be performed from the early stages of development, and resources can be used optimally.
Among many infrastructure elements, integration to cloud environments and container-oriented clusters (especially Kubernetes) are among the most common uses. Since many Machine Learning projects deal with protected data that cannot be captured, read, or manipulated outside of a safe environment, both cloud and on-premise support should be considered.
Integration with data sources and data sinks is also of primary importance — a pipeline solution that doesn’t provide such kind of integration over a wide range of database and message interfaces will be severely restricted once a project leaves the development phase and reaches the systems in which it should be integrated.
If a workflow framework can provide reliable, out-of-the-box integration to databases and can also make use of both on premise and cloud-based infrastructures, configuration times will be reduced and many projects will become agnostic to these back-end decisions, greatly improving the ability to update and development speed.
Another key aspect to be considered on a workflow framework for Machine Learning is its integration with serving solutions. Models have little more than analytical utility when they’re not readily available to be used by the end applications and, even when they’re not real time nor exposed to final users, the time between solution development and usage might be severely limited by its integration and accessibility with other systems.
Even though a workflow framework shouldn’t be fully responsible for final deployment, it should offer tools to expose triggers and results in an efficient and modular way that can be easily modified and updated.
Finally, a workflow framework should not only be reliable, stable and well connected, but it should also help the development of prototypes, new projects and early analysis. In many cases, these steps are done completely outside the development and production environments, since these would add unnecessary overheads to exploration and analysis. If a workflow framework can, at the same time, help the development of early prototypes without additional overheads and also provide a seamless progression of other steps of development, it won’t hamper innovation nor add an unnecessary tradeoff between usability and integration.
Workflow solutions: implementation alternatives
Workflow solutions may seem simple enough to be custom made, when only the high-level functionalities are considered: simple sequences of tasks can be defined by chaining script calls, and by implementing everything with a script language it would be possible to have a light-weight solution that allows modular definition and execution of pipelines. A more in-depth analysis, however, will reveal a couple of key issues with this approach:
- Integration with other systems must be done manually and will often require specialists on each system and technology, including databases, languages and message systems.
- System maintenance, including addition of new features and updates will be required every time one of the dependencies receives a major update. While this is not an issue for other types of solutions, a workflow solution that provides integration will frequently deal with different tools and technologies that update independently.
- More complex workflow structures (that offer multiple paths or conditions) and orchestrators must be implemented from scratch, and might not be as trivial as simple pipelines
- Finally, distributed management of tasks is a complex operation that requires not only experience with platforms such as Kubernetes but also a considerable amount of testing, considering multiple possible configurations, system limitations and issues.
This means that, unless the expected solution is fairly simple and doesn’t need to be robust on diverse platforms, a custom-made workflow solution could end up being costly to implement and, specially, to maintain.
Among the solutions available on the market, two groups can be found: the specialist frameworks and the generalist frameworks. Specialist frameworks include many features that help with specific tasks, but lack broad integration with multiple systems or flexibility to integrate completely new solutions.
As an example of a specialist framework for workflows, Kubeflow is a Kubernetes-based workflow solution based on Google Cloud Services (GCS) and focused on machine learning applications. It provides many interesting features such as native integration to Jupyter Notebooks, experiment tracking and hyper-parameter optimization. On the other hand, it’s also a fairly heavy solution — it requires 72 pods to run all of its functionalities, and is best optimized to run specifically on GCS platforms. While they do offer some solutions for other cloud providers such as Azure and AWS, not all features are available in all of them, and their support for on premises clusters (which are common in projects with highly sensitive data) is limited.
In general, Kubeflow seems like a good solution for projects that are starting from scratch, without need to integrate to existing systems and centered on development of ML models. However, for projects that are already well consolidated, with multiple requirements and limitations already defined in a Kubernetes environment, integration might be hard to achieve and costly. While they do provide good integration to very specific tools that help during the Exploration and Development phases of a data project, in many projects it’s often the case that the best solution is one that supports existing systems and allows them to grow and develop, covering multiple phases of development (from exploration to maintenance) and different areas (such as tests and deployment).
On the other end of the spectrum, Apache Airflow is a lightweight, generalist solution for workflows that’s meant to integrate with existing systems and provide them a robust platform for pipelines. Even though it doesn’t include specialized tools for ML, this integration would allow these workflows to help not only during exploration and development but also during deployment, production and maintenance.
The next section explores more in depth the key characteristics of Apache Airflow and how they can be used to support all phases explained in the previous sections.
Apache Airflow

Apache Airflow is a generalist pipeline solution intended to support different types of tasks and executors in diversified environments — from local setups to distributed, Kubernetes-based clusters. It also offers a robust infrastructure that allows interaction and maintenance of pipelines with integrated schedulers, web servers and loggers. Finally, it also provides a high level of integration with many types of data sources and execution engines, supporting a wide range of applications.
This framework is based on four key concepts: DAGs, Tasks, Operators and Executors:
- DAGs, short for ‘directed acyclic graphs’, are Apache Airflow’s pipelines. They can be defined as a series of tasks with a directed dependency relationship, which describe a workflow. These DAGs can be either defined explicitly — by connecting Tasks — or implicitly, by simply calling annotated functions which will be later translated into a graph. DAGs are managed by Apache Airflow, from triggers and APIs to message passing, and the framework also provides metadata, logs and visualization tools over it without extra configuration.
- Tasks are the ‘building blocks’ that form DAGs, and define specific actions that must be performed. They can be customized, parametrized and shared among distinct DAGs, improving reuse and adding flexibility to development. Each task is built on top of an Operator.
- Operators are base task types, which provide Airflow the capacity to perform all kinds of activities. They go from operators that execute source code (such as PythonOperator) and scripts (such as BashOperator) to database watchers (such as PostgresSensor) and even pod spawners (such as KubernetesOperator). Custom operators can also be defined by performing tasks on specific or proprietary systems which implement certain Apache Airflow interfaces.
- Executors, finally, define how and where the tasks (which are operator instances on a DAG) will be performed. They range from fairly straightforward LocalExecutors, which will execute each task one by one, together with the scheduling process; down to CeleryExecutors (which use Celery to spawn Worker pods and distribute tasks to them) and even KubernetesExecutors, which will automatically spawn new pods in the Kubernetes environment, provide all necessary data required, run the tasks, return the results and finally remove the created pods.
This set of features allows Apache Airflow to natively integrate with other solutions:
- Data sources can be connected to Apache Airflow through modularized sensors — both those that are already implemented in the package or those customized over predefined interfaces.
- Similarly, outside connections can be established through Apache Airflow’s REST API, which comes with access control and exposes both information and control over DAGs and DAG executions by default.
- Many types of existing infrastructure, including Kubernetes clusters, can be used from the start and in a completely seamless way to data scientists. Executors can be configured independently from DAGs and tasks and configured to make optimal use of resources through workers of ephemeral pods.
- Logging, traceability and historical information are also covered by Apache Airflow without the need of additional implementation nor overheads on the development side. Logged data can also be accessed through their UI, through REST APIs or directly from their metadata database.
This set of features is very convenient for a wide range of applications, and is not limited to data science projects. In fact, Apache Airflow’s generalist approach allows different types of projects to be built on top of its base structure, and Executors can be parameterized in order to reserve different resources for different DAGs or applications.
These characteristics, even though helpful for general development and desirable in a data science environment, don’t cover by themselves the full set of requirements described in an earlier section. In order to fully enhance data-related projects, improvements to Exploration, Development, Deployment and Production are also expected — or, in broader terms, a strong support to both prototyping new solutions and maintaining the complete lifecycle of a project, from concept to production.
The first point in which Apache Airflow can help comes from its generalist outlook: since it’s based on modular tasks and configurable DAGs, individual tasks can be shared among distinct projects, common DAG structures can be fully reused, and development can be done iteratively by replacing specific tasks with compatible interfaces.
As an example, consider a simple, generic pipeline for early model exploration:

First of all, in Apache Airflow each execution of this DAG will be properly recorded in a metadata database, enhancing traceability and accountability.
This base structure can be pre-defined, and each of these tasks can come with any required pre-implemented logic that suits a company — extra security protocols, default access configurations, built-in repositories — that will always be available by default.
Then, data scientists can focus on preprocessing, training and test tasks over a set of static data by simply replacing the LOAD task (or its implementation) with a local variation. At a later point, when actual/live data is available, a single module will require replacement — and this module (which doesn’t need to be implemented as python code, since Apache Airflow allows tasks to have different types of Operators) can be managed and implemented by specialized Data Engineering teams, independently.
As the project progresses, the same task implementation can be enhanced as they move from exploration to actual development, including DAGs with more tasks, and even up to deployment. Since all of these steps can be done over the same structure, integration errors will be minimized and even development costs will be reduced, since a single “transparent” environment will be used.
Executor configuration can be evolved from Local to Worker-based or Kubernetes-based without any direct interference on specific tasks, keeping both the tasks and the infrastructure fully decoupled.
A more detailed description of Machine Learning Operation over Apache Airflow can be found in the following section.
Airflow for ETL and Data Lineage
ETL (acronym for Extract, Transform and Load) is the process of extracting data from different sources, transforming it by applying filters, interval normalization, calculations (or even derive new information from data collected), and then load the transformed data into a unique and concise data storage system (usually data warehouses). Once ETL is one of the most vital processes of a data-oriented business, building a robust and scalable ETL pipeline is essential.
Using Apache Airflow, data engineers can build really complex ETL pipelines relatively simply. For example, in the “Extract” stage, we can take advantage of the multiple operators developed by the community to extract data simultaneously from several different technologies, such as PostgreSQL, Apache Cassandra, Amazon S3, etc. If an extraction task fails, we can use the retry mechanism to re-run the task again after a certain period of time. Also, in case an ETL pipeline can only occur after all the data is available, we can use the concept of sensors to automatically start the pipeline as soon as all the necessary data is detected. In the “Transform” step, we can take advantage of the parallelism of the Apache Airflow scheduler to execute several transformations tasks simultaneously as the data is extracted.
It is very important for data professionals to well understand the data and all the changes it has undergone along the way in order to identify possible errors in data processing, fix incorrect assumptions about it that may skew analysis and ensure high quality data.
Thanks to Airflow’s flexibility, we can define new operators and custom plugins to maintain a complete logging of all the data, including data source, schema, owner, when it was extracted, what transformations were applied, what problems occurred during the extraction, etc. Alternatively, data engineers can integrate Airflow with other metadata management systems (such as Marquez) to ensure high quality data lineage with less implementation effort. These implementations can be done once and used in a modular way in many workflows, providing code reuse and high maintainability.
Airflow for Machine Learning Pipelines
In addition to data pipelines, Airflow’s great power makes it an optimal option for creating machine learning pipelines in both development and production environments.
For example, imagine a typical ML pipeline that starts from data collection to deployment. Through Airflow we can create robust, scalable and reproducible ML pipelines from centralized source codes where each node of Airflow DAG is a step in our ML pipeline, like model training and validation. Together with versioning control and experiment tracking tools, we can define a DAG template and then keep an automatic track of the version of data used for model training, parameters learned and hyperparameters used, training and test time, binary format of model and all dependencies necessary to build this exact model again. We can also use Airflow to implement Continuous Training. More precisely, we can take advantage of its sensors to trigger a model-specific retrain pipeline regularly (e.g., every Friday at 9am) or as soon as certain data is available.
Furthermore, there are several tools dedicated to the creation of ML pipelines that use Apache Airflow as an orchestrator. A classic example is TensorFlow Extended (TFX), an end-to-end platform for creating and deploying production-ready ML pipelines.
Key Takeaways
Despite its many advantages, using Apache Airflow — and workflow orchestrators in general — doesn’t come cost-free and might not be suggested for all scenarios.First of all, even the lighter solutions are meant to be executed on dedicated environments, so it might not be advisable for projects with strict hardware limitations (such as embedded systems).
Second, workflows will require a certain level of overhead, not only on implementation but also on expertise. The added implementation cost usually covers itself if one or more projects are developed end-to-end, but if no prototypes have ever been developed, creating a full ecosystem of execution beforehand might not be advisable. Workflow solutions require projects with a level of maturity in which maintainability and reproducibility are key interests.
It’s also important to notice that, even if development of Apache Airflow tasks and DAGs is rather simple and it provides integration with many different technologies, these integrations are not always straightforward and might require further specialization. For example, usage of Kubernetes-based resources on Airflow requires some knowledge on Kubernetes configuration, at least during initial setup.
Finally, Apache Airflow (and many other workflow solutions) are not complete solutions meant to support all kinds of execution structure. Real time data streaming and finite state machines, for example, are not fully supported by Apache Airflow, and might require integration with other solutions. It’s always possible to use workflow solutions as high-level frameworks that integrate other, more specific solutions underneath, but each case should be studied separately.
Conclusions
Workflows are an invaluable tool for data engineering pipelines and, specifically, Machine Learning applications — not only for the usual automation applications but also as an auxiliary tool for exploration and development. Adopting workflows as a base structure for ML/DS development can improve the whole process and drastically reduce the time from prototype to deployed product, and it’s also useful to generate maintainable, reusable and modular source codes.Among the available technologies and frameworks for data-focused workflows, Apache Airflow is on the most versatile and robust implementations, thanks to its lightweight, flexibility and easy integration to other technologies. The large community and its native support to a myriad of other solutions makes it a good bet for data projects that are meant to be integrated with other pre-existing systems, while specialized solutions such as Kubeflow can be more beneficial for new projects that don’t rely on such integrations.
Acknowledgment
This piece was written by Ivan Caramello, Data Scientist at Daitan. Thanks to João Caleffi, Thalles Silva and Kathleen McCabe for reviews and insights.References
- Apache Airflow: https://airflow.apache.org/
- Kubernetes: https://kubernetes.io/
- Kubeflow: https://www.kubeflow.org/
About Encora
Fast-growing tech companies partner with Encora to outsource product development and drive growth. Contact us to learn more about our software engineering capabilities.

