Introduction
The growing demand for machine learning solutions (ML henceforth) in the mainstream market has created a need for a structured and efficient approach to developing ML projects. This led to a sudden rise in demand for ML engineers, data scientists, data engineers, and other machine learning-specific jobs. ML engineers apply established DevOps (software development + IT operations) best practices to the emerging machine learning technologies. This is why MLOps (machine learning + IT operations) is gaining traction and adoption.
MLOps is the process of automating machine learning using DevOps methodology. MLOps inherited the same values and practices from DevOps, like automation. There’s an expression in the DevOps community that states that “if it is not automated, it’s broken”.
The same applies to MLOps. We should strive to reduce or eliminate all types of manual intervention (friction) from ideas up to the deployment of the machine learning model in production. MLOps allows creating a flow of business value. We’ve learned that humans are terrible at doing manual repetitive tasks because they are fallible, after all, making mistakes is inherent to the human being.
But there is a key difference between DevOps and MLOps that makes the former not immediately transferable to machine learning projects: deploying software into production is different from deploying machine learning models into production.
While software code is relatively static, machine learning is generally trained on data taken from the real world, and real-world data is always changing. Thus, machine learning models should be ready to constantly learn and adapt to new data. While traditional software development is driven by code, ML is driven by data. The fact that machine learning models are made up of code, data, and configuration (parameters, hyperparameters, sampling methods, random number generators, etc.) and the need to adapt to a complex and ever-changing environment, is what makes MLOps a new discipline.
The model training and deployment is a new process that must be added to the traditional DevOps lifecycle. Monitoring and instrumentation should be in place to check things that can break and are unique to ML, like concept drift (the changes in the data distribution from the last time the model was trained that could lead to incorrect predictions or results). A big friction factor in deploying machine learning models into production is the immaturity of the field and lack of standards. Given the software discipline has adopted DevOps to solve similar issues with high success, the machine learning community is embracing MLOps now.
What is MLOps?
Traditionally, machine learning projects were approached from an individual and relatively manual perspective, where a data science or machine learning expert trains a model and deploys it in production. However, as machine learning becomes critical to business strategy, more and more people and other systems become dependent on these solutions. It is at this point that the production of machine learning solutions can become a bottleneck and cause friction in the value delivering flow because of the manual interventions, impossibility to reproduce models, complications to testing, difficulty to scale, unintuitive predictions, among others.
In addition, ML experts often use tools, frameworks, and infrastructure that differ from those used in traditional SDLC, so the need for standardization becomes an important issue. Therefore, it is necessary to apply and adapt the best software engineering practices to machine learning solutions. These practices include unit testing, continuous integration, continuous delivery, continuous deployment, infrastructure as code, etc.
Machine learning systems promise to solve business problems, while MLOPs promise to accelerate the return of investment of those ML systems. The objective of MLOps is to reduce technical friction, minimize risk, and decrease the time it takes to develop an ML solution, from the moment it is born as an idea until it is deployed in production (including maintenance and retraining processes). In other words, MLOps seeks to manage the lifecycle of machine learning applications at scale, where multiple individuals, teams, and business units may have potentially disparate needs.
For example, machine learning models tend to consume a lot of processing power (which ultimately translates into money), this could involve the company's IT department or the finance department. Another example is that machine learning produces knowledge from data, this data could contain sensitive or personal information, so the legal department of the company may impose restrictions. Legal teams may also want to review & ensure that the training data & resultant models are ethical & fair. One last example is that automation is a prime requirement for software engineers (development department), however, the tools or processes that machine learning experts use could pose automation challenges.
In general, machine learning projects impact all company’s departments and MLOps must help to reduce any potential friction.
The MLOps flow
Most of the literature on machine learning states that the life cycle of a model is made up of a series of steps that occur one after the other and are constantly repeated. These steps are:
● Development of a model:
○ Determine the business need
○ Exploratory data analysis
○ Feature engineering
○ Training and evaluation
○ Reproducibility
● Deployment in production
● Monitoring
● Maintenance:
○ Iteration or retraining
○ Feedback
● Governance
In theory, the life cycle of a model should look like this:
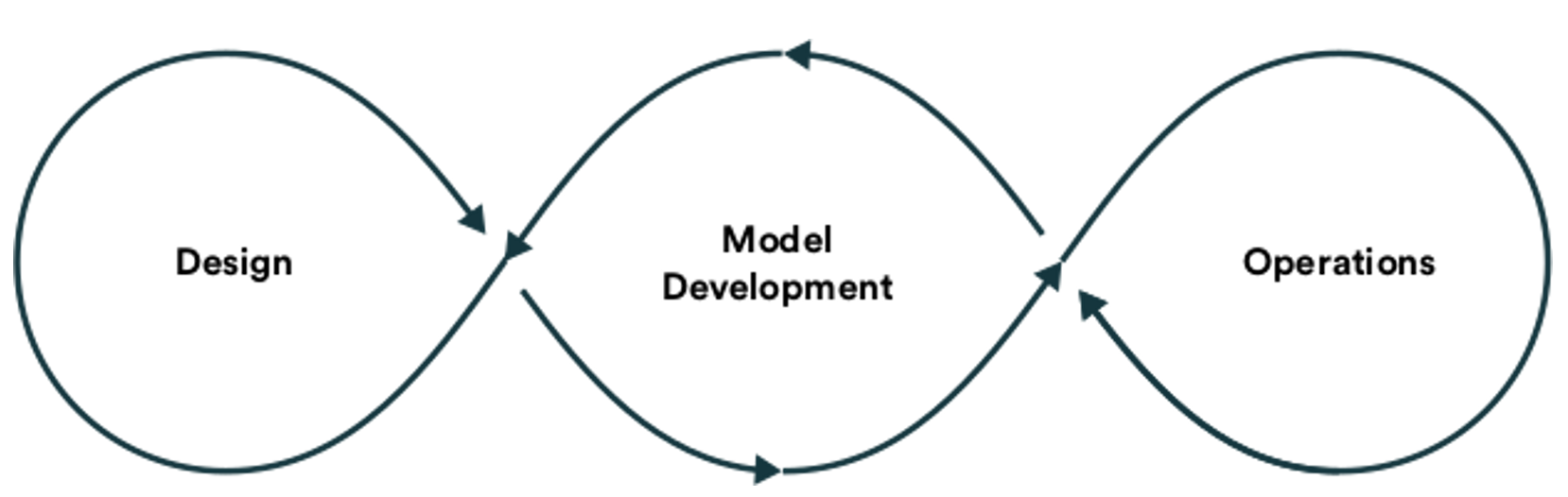
Note how the image suggests a smooth process, free of blockages and friction.
However, the reality in most companies looks like the following image:
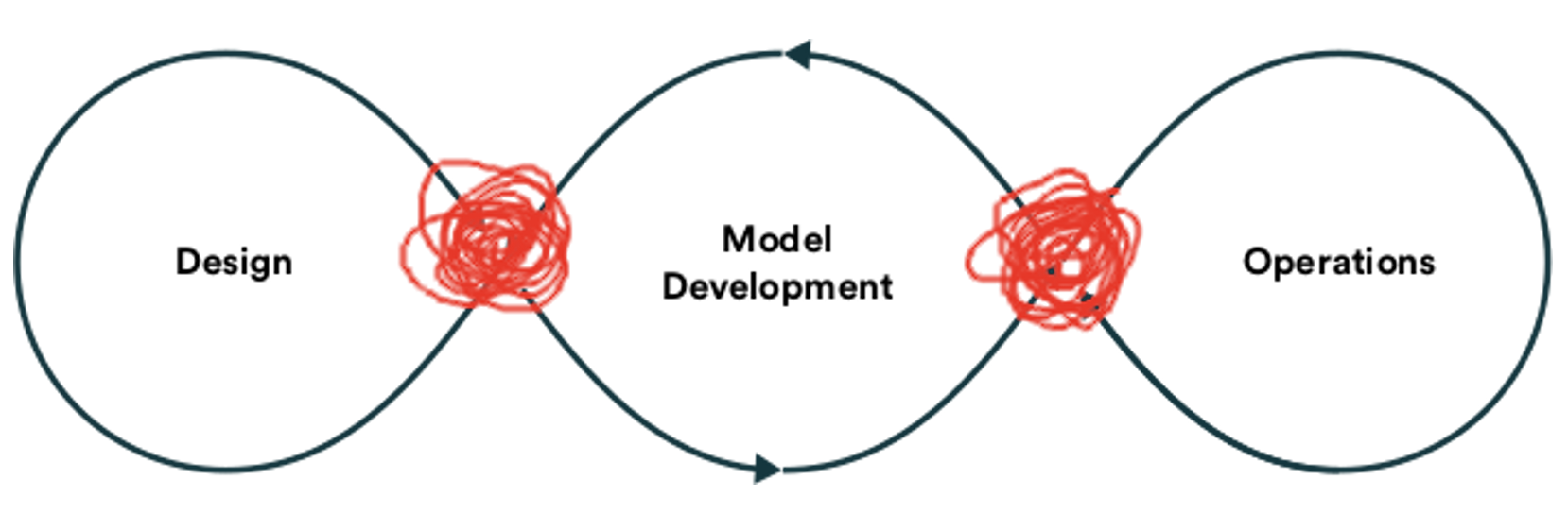
Those broken or congested paths (in red) mean that there are bottlenecks, friction, and/or manual intervention in the ML’s value flow.
MLOps seeks to reduce the friction between the steps, aims to increase the reproducibility of the entire life cycle of the model, and aims to automate any manual process as much as possible, allowing the leap from the development of machine learning models on a "lonesome" small scale (i.e., a single data scientist) towards a professional development where many multidisciplinary teams are involved and where concepts such as scalability, performance, availability, monitoring, reproducibility, automation, efficiency, auditability and satisfaction of the objectives of the company (and customer) acquire relevance. Just as DevOps decreases the friction between development and operations, MLOps introduces ML into the equation.
Although it is fun to develop alone and, in a vacuum, the reality is that only a model that runs in production can provide value to the organization. The models have zero return on investment until they can be used. Therefore, the time to market is one of the metrics that are usually optimized in ML projects.
The goal of MLOps is to reduce technical friction to get the model from idea to production in the shortest possible time and with as little risk as possible.
MLOps creates a feedback loop that usually includes the following:
● Create and retrain models with reusable pipelines: Creating a model once isn’t enough, reproducibility is required. The data can change, the customers can change and the machine learning experts making the models can change. The reality could change since the last time a model was trained.
● Continuous delivery/deployment of ML models: Continuous delivery of ML models is analogous to continuous delivery of software. All the steps required to recreate a model from zero to deployment must be automated, including the infrastructure. Using automation, a model must be deployable at any time to any environment.
● Audit trail for MLOps: It is critical to have auditing in place for all the phases of the MLOps flow. There is a huge list of things that could go wrong in a machine learning project, including security, bias, overfitting, underfitting, accuracy, etc. Hence, having an audit trail and adequate logging is critical.
● Monitoring: One interesting aspect of ML is that data (the reality) changes after a model is trained. Therefore, the model that worked for customers some time ago probably won’t work anymore (retraining is required). So, MLOps must monitor data drift and model performance constantly to prevent accuracy problems.
MLOps challenges
On the surface, going from a business problem to a machine learning model seems straightforward. For most traditional organizations, the development of ML models and their deployment in production is a new endeavor. The number of models can be manageable at a small scale. But with an increasing prevalence of decision-making that happens without human intervention, models become more critical, and managing its risks becomes more important for the entire organization.
Managing machine models at scale is difficult for the following reasons:
● There are many dependencies: Not only does data constantly change, but business needs change too. The stakeholders need to be informed about the ML model to ensure that its performance aligns with expectations (reality) and meets the original goal.
● Polyglot development: The machine learning life cycle requires people from the business, data science, development, IT operations, but it’s extremely rare that these groups use the same tools or have the same experience developing ML projects.
● Data scientists are not software engineers: Machine learning experts are specialized in model development, and they are not necessarily experts in writing traditional software applications. Additionally, they usually use their own tooling that differs from traditional SDLC standards. The problem increases in complexity when ML becomes a core asset in the company and support of multiple models in production is required. New concerns like performance, scalability, availability, maintenance & explainability need to be addressed at this point so software developers, software architects, DevOps specialists, and data engineers need to come together.

Conclusion
Organizations are investing in machine learning to solve business cases that are impossible to solve using traditional software development techniques, as an example, automatically detecting fraudulent transactions. MLOps comes with the promise to accelerate the return of your investments in machine learning. MLOps won’t provide immediate results because its implementation in a company requires effort, requires commitment from the organization’s stakeholders. It requires a change in the organization’s culture. But once in place, the MLOps processes will yield huge benefits to the company’s machine learning strategy.
The four critical MLOps best practices that must be adopted are:
● Versioning to ensure reproducibility of models.
● Pipelines to build better machine learning systems collaboratively.
● Testing to set standards for production models.
● Automation to save time and provide self-healing systems.
The goal of MLOps is to reduce technical friction to get the model from an idea into production in the shortest possible time with as little risk as possible in order to deliver business value.
Let's work together and create new strategies together!


