
Have you ever heard about GraphQL? In this article we introduce you to this API standard that is increasingly being adopted across companies. We go through the basics, and see how it works behind the scenes. Thereafter, we observe how to aggregate multiple GraphQL microservices (subgraphs) into a single powerful Supergraph Gateway. Finally, we identify the main advantages and disadvantages of using GraphQL.
GraphQL
GraphQL is an API standard that provides an efficient, powerful, and flexible way to retrieve and modify data. It was developed and open-sourced by Facebook, and now it has a large community maintaining it [1].
GraphQL works by sending operations to an endpoint. There are three types of operations: queries, mutations, and subscriptions. A query is sent through an HTTP POST call to retrieve data. A mutation is also sent through a HTTP POST and is used to modify data. A subscription uses WebSockets to receive events.
It’s possible to send more than one query or mutation in a single call, but it’s not possible to mix different types of operations. In addition, to keep consistency, queries run in parallel whereas mutations run sequentially. It’s also important to mention that it’s common to hear the term query being used to represent an operation (query, mutation, or subscription), but we don’t do this here to prevent confusion.
In a GraphQL operation, the client can precisely select the data it needs [1]. This is different than REST, which has multiple endpoints that return fixed data structures. This approach brings some advantages like efficient data loading, interoperability, and fast development. We discuss them further in a separate section in this article.
Figure 1 shows that a GraphQL API is a layer that relies on data sources. You should write a business logic layer to authenticate/authorize requests, validate inputs, get data from a database, RESTful web service, legacy system, or external GraphQL API. You can also consume messages from a queue and send them to the clients through a subscription operation. There are some libraries that help to write this business layer. Note that GraphQL is also a technology that fits well to modernize legacy systems without the need to modify them.
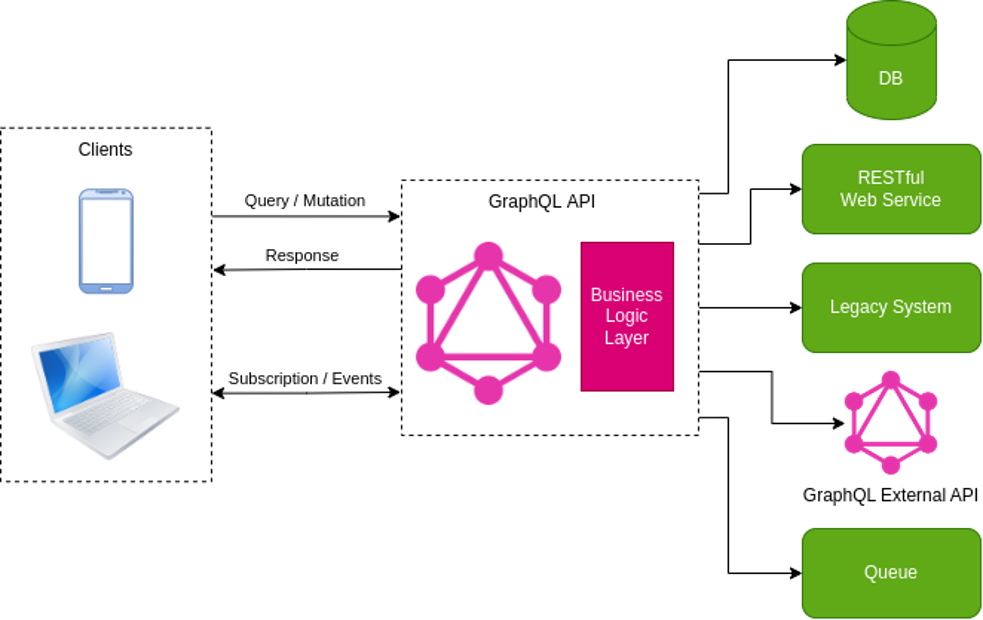
Figure 1 – GraphQL architecture
Behind the Scenes
A GraphQL API defines a set of types that describe the structure of all fields and objects, which we call the GraphQL schema. The schema is useful for clients to understand the inputs and predict the outputs of any operation. Also, the API uses the schema to validate operations and returns execution errors in case of unexpected types.
Figure 2 shows an example of a GraphQL schema:

Figure 2 – Example of a GraphQL schema
Besides Query and Mutation types, the schema has two types: User and Product. The User type has fields: uid, firstName, lastName, age, and purchases, whereas the Product type has fields: pid, name, and price. Beside each field, we can find its type. Note that an exclamation mark means the field is non-nullable.
The Query and Mutation types are the types corresponding to the GraphQL operations we discussed previously. They define the entry point of every GraphQL query or mutation. The user query and the buyProduct mutation have input arguments in parenthesis.
Given the schema above, the items below and Figure 3 explain how a GraphQL query happens from the HTTP call until the data is returned to the client:
- Client sends a POST request with some headers (“Content-type”, “Authorization”, etc.) and a request body containing a query field with the GraphQL operation details. There are two other optional fields that can be sent in the body: variables and operationName. The former allows the client to pass some variables to be replaced in the server. The latter is the name of the operation that can be used for logging purposes, for example.
- Server extracts the query string from the request body, parses and validates it.
- Server checks authentication and authorization for the current request.
- Special functions called resolvers populate the data by querying required data sources. Each field from the query is loaded by a single resolver. However, a resolver can be used by more than one field at the same time. In Figure 3, the user resolver returns all subfields inside the user field, except for the purchase fields, which are populated by the purchases resolver.
- Server returns the collected data (JSON format) inside a data field in the response body. Note the similarity between the GraphQL query and the response body: both follow the same structure.
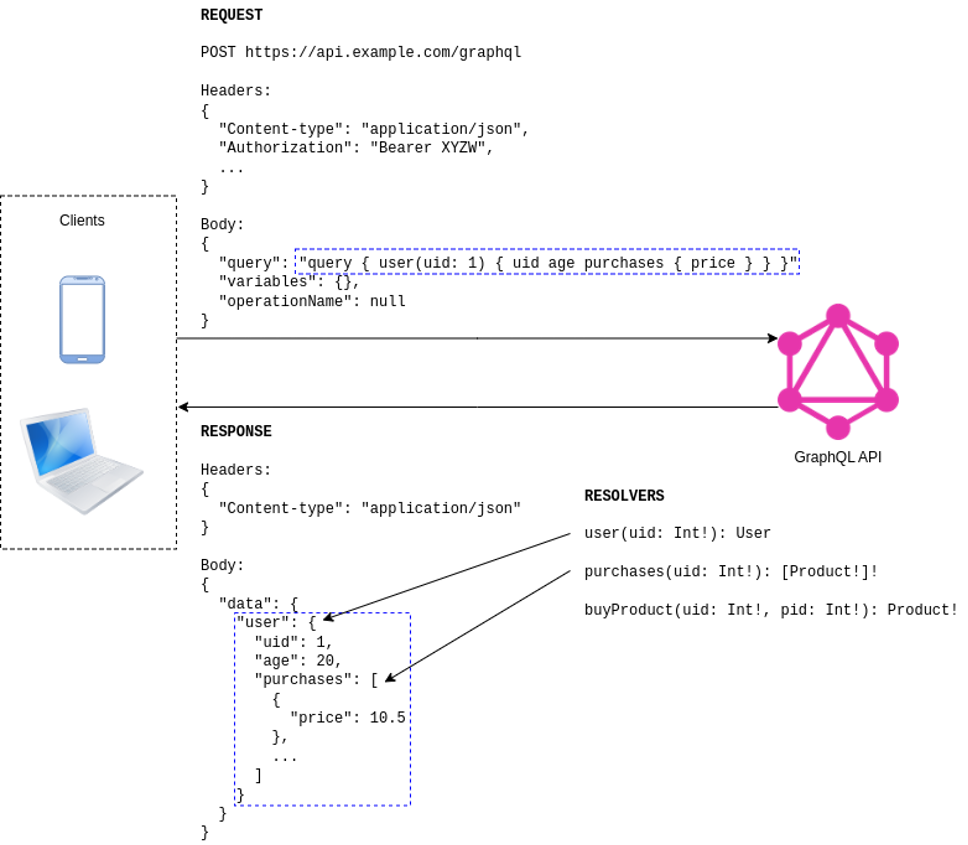
Figure 3 – GraphQL request/response over HTTP. Based on [3]
A similar flow happens with mutations. Subscriptions work similar too, except they are called through a WebSocket and the client keeps receiving data whenever it’s available.
GraphQL Federation
How can we divide a GraphQL API into smaller microservices? We can use a Supergraph Gateway that joins the schema from a set of microservices (called subgraphs) and communicates with them. The clients should call the Gateway instead of the individual subgraphs. This technique is called GraphQL federation.
The Supergraph Gateway combines the schema from all subgraphs and provides a final schema for the clients. While combining the schema, it also stores additional information to know which types and fields each subgraph is responsible for, and how to intelligently distribute GraphQL operations across them [5].
Regarding the schema composition architecture, there are two possible approaches. Figure 4 shows the first and simplest one, where the GraphQL Gateway directly creates a federated schema based on the schemas from the connected subgraphs (User and Product Subgraphs).
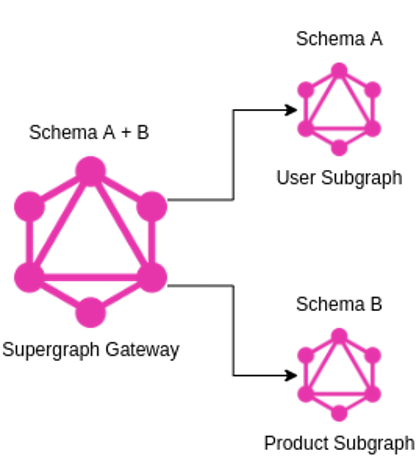
Figure 4 – GraphQL Federation with automatic schema composition
The main disadvantage of this approach is the schema composition happens during the Gateway startup. Thus, each schema change requires the gateway to be restarted. This is also risky, because if the composite schema is not a valid federated schema, the Gateway won’t start and the entire Supergraph won’t be available. That’s why there is a second approach, called managed federation, shown in Figure 5:
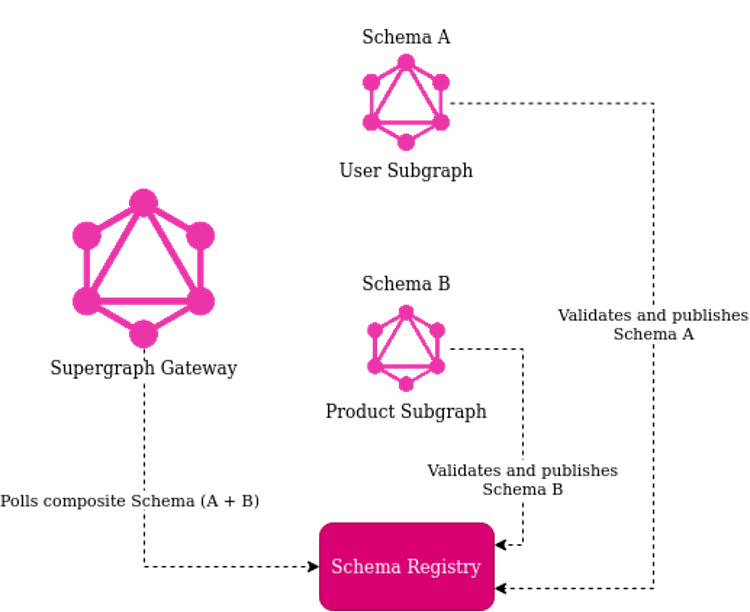
Figure 5 – GraphQL Federation with managed schema
With this approach, each subgraph can verify if its proposed changes will be a valid federated schema along with all other registered schemas [9]. If so, they can publish their schema to the Schema Registry and the composite schema will be updated in the Gateway without the need to restart. If not, the Gateway will continue to use the last valid federated schema. This approach is more complex to implement, but you shouldn’t have downtime of the entire Supergraph due to schema failures.
The client consumes the composite schema, but how to split the schema among different subgraphs? The best approach is to separate by concerns, not by types. Figure 6 shows an example on how to split the example schema we have seen in Figure 2 among two subgraphs:

Figure 6 – Splitting the example schema among different subgraphs
Note this split is straightforward, except for the changes represented by the arrows. The key point is each subgraph should define types and fields it can resolve. Thus, the User type is defined twice, but each subgraph defines parts of it.
Splitting more complex schemas requires understanding of all the schema composition rules, which can be found here [8]. In any case, with this approach it’s easy to grow the schema by adding new subgraphs. Therefore, it’s a good fit for a microservices architecture.
Advantages and Disadvantages
Now that we understand the main GraphQL capabilities, it’s time to check the advantages and disadvantages of adopting it:
Advantages:
- Efficient data loading. GraphQL minimizes the amount of data transferred from the server, thus decreasing network usage. This is very important for mobile and low-powered devices, especially when connected to a bad network [1].
- Interoperability. As the clients can select the data they need, it’s easy to provide compatibility with different clients.
- Good for modernizing legacy systems. It’s easy to add GraphQL in front of legacy systems, so providing a more modern API without the need to change the legacy APIs.
- Good for microservices. GraphQL Federation facilitates the development and integration of microservices a lot. As an example, Netflix has been using this technique to integrate its large number of microservices [11].
- Fast development. Thanks to the GraphQL flexibility, development changes are reduced, because the server can expose all possible data and the clients can get all required data within a single query, without major adjustments. Clients can also use GraphQL fragments, which are snippets of logic that can be shared in multiple operations [7]. More details can be found here.
Disadvantages:
- Overkill for small applications. Depending on your application needs, GraphQL may be overkill. Sometimes you just need a simple REST API with a small set of endpoints.
- Performance issues with complex queries. GraphQL gives a lot of power to the clients. So, it’s necessary to add some protection in order to prevent the server from going down. Some practices to mitigate this risk include configuring timeout, maximum query depth, maximum query complexity, and throttling [2]. More details can be found here.
- Harder to integrate with monitoring tools. GraphQL returns 200 OK for errors, so it will be harder to integrate with monitoring tools [10].
- Only JSON support. This may not really be an issue since JSON is the most used data format in APIs. However, if you need XML for example, GraphQL is not the right choice.
- Lack of automatic HTTP caching mechanism. GraphQL uses a single endpoint with many different operations, so it’s not possible to use HTTP caching [4].
Conclusion
In this article we introduced GraphQL and exposed some important concepts like GraphQL operations, schema, and federation. You should now have a general idea of its main capabilities and can evaluate better whether GraphQL is a good fit for your project.
References
[1] howtographql.com. Basics Tutorial – Introduction. https://www.howtographql.com/basics/0-introduction/
[2] howtographql.com. Security. https://www.howtographql.com/advanced/4-security/
[3] hasura.io. What is GraphQL? https://hasura.io/learn/graphql/intro-graphql/what-is-graphql/
[4] hevodata.com. GraphQL vs REST: 4 Critical Differences. 2021. https://hevodata.com/learn/graphql-vs-rest/
[5] Apollo Docs. Introduction to Apollo Federation. https://www.apollographql.com/docs/federation/
[6] Apollo Docs. Managed federation overview. https://www.apollographql.com/docs/federation/managed-federation/overview/
[7] Apollo Docs. Fragments. https://www.apollographql.com/docs/react/data/fragments/
[8] Apollo Docs. Schema Composition. https://www.apollographql.com/docs/federation/federated-types/composition/
[9] Apollo Docs. Federated Schema Checks. https://www.apollographql.com/docs/federation/managed-federation/federated-schema-checks
[10] HERRERA, S. Why you shouldn’t use GraphQL. 2021. https://blog.logrocket.com/why-you-shouldnt-use-graphql/
[11] Netflix Technology Blog. How Netflix Content Engineering makes a federated graph searchable. 2022. https://netflixtechblog.com/how-netflix-content-engineering-makes-a-federated-graph-searchable-5c0c1c7d7eaf
Acknowledgement
This article was written by João Sávio Ceregatti Longo (Principal, Systems Architect and Tech Lead) and Adilson Dutra Teixeira Filho (Software Developer). Thanks to Ricardo Mogio, João Caleffi, Isac Souza, and Kathleen McCabe for reviews and insights.
Further Reading
Architectural Design Patterns: Microservices Architecture
All You Need to Know About API & API Testing
About Encora
Fast-growing tech companies partner with Encora to outsource product development and drive growth. Contact us to learn more about our software engineering capabilities.


