Since its announcement, ChatGPT has changed the AI landscape and transformed the way people engage with AI systems. This disruptive technology has bridged the gap between AI and everyday individuals, while also driving organizations to search for ways to leverage the power of Large Language Models (LLMs) in their businesses.
The excitement surrounding this subject shows no signs of fading and there is a good reason for that. LLMs are able to understand users’ prompts and generate coherent responses for a wide variety of tasks, including translation, summarization, question-answering, content creation, and others, thanks to the vast amounts of data they were trained on.
The problem
While LLMs perform well in many scenarios, they struggle to give relevant answers to questions that go beyond their training data. In particular, they are not able to generalize and answer questions accurately about recent events. For instance, as of the moment, this blog post was written, ChatGPT training data goes up until September 2021, so it would not be able to satisfactorily answer a prompt like the following:
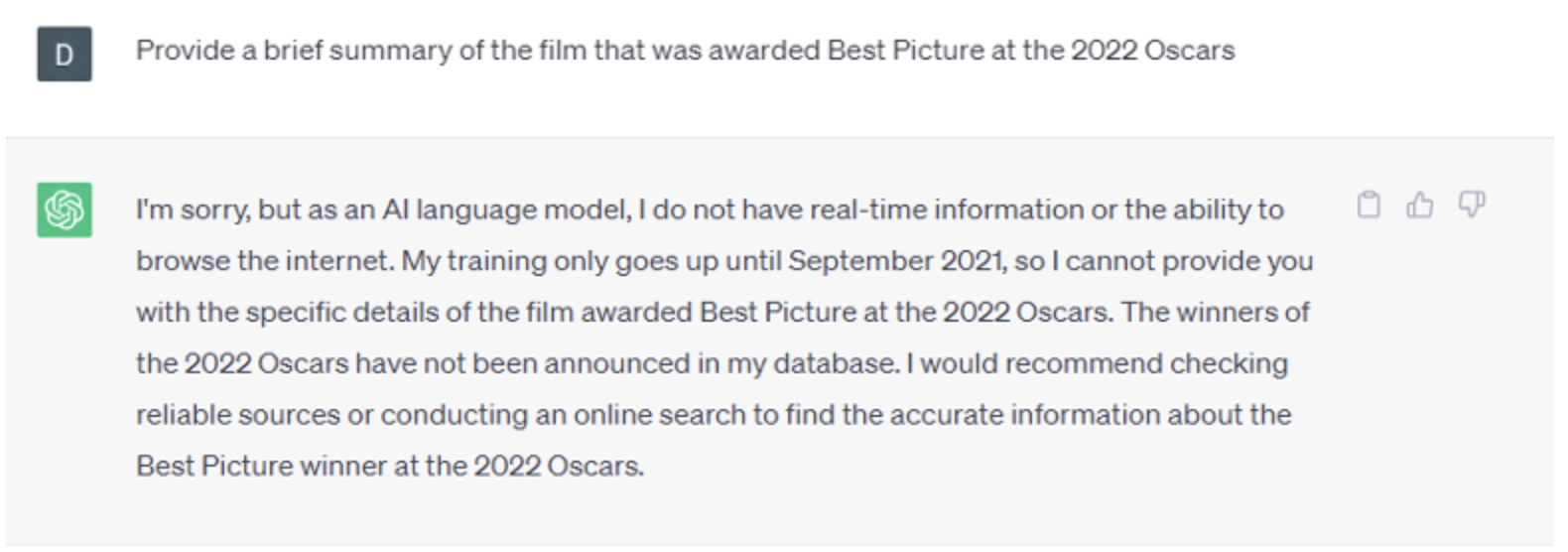
Figure 1: ChatGPT Output - Conversation about recent data
There is also the problem of using these tools with private documents. If we were to use a standalone LLM without considering privacy implications, we would need to manually input the document’s text ourselves, accounting for the token limit per request of the model.
In this sense, this post will briefly explore some options that can be considered to address LLMs limited knowledge of recent events. More specifically, we will use some tools to ask questions about recent information available on the Internet and PDFs.
Exploring approaches for Q&A over documents
LLMs can be fine-tuned for specific tasks or domains with new data. However, training these large models has high computational requirements and cost implications. They also require some expertise from the user to be able to fine-tune them.
For some use cases, however, we don’t need to gather data and fine-tune a model ourselves. Using AI-powered search engines for combining search results with LLM capabilities and other integrations for ingesting new data into LLMs should be enough.
Search Engine and Plugins
For instance, if we want to simply ask a question about recent events, we could leverage the new advancements in AI-powered search provided by services like Microsoft’s Bing Chat and Google’s Bard.
We can use the same prompt as before, and the Bing chat is able to answer the question accurately while also providing sources for its statements and image suggestions.
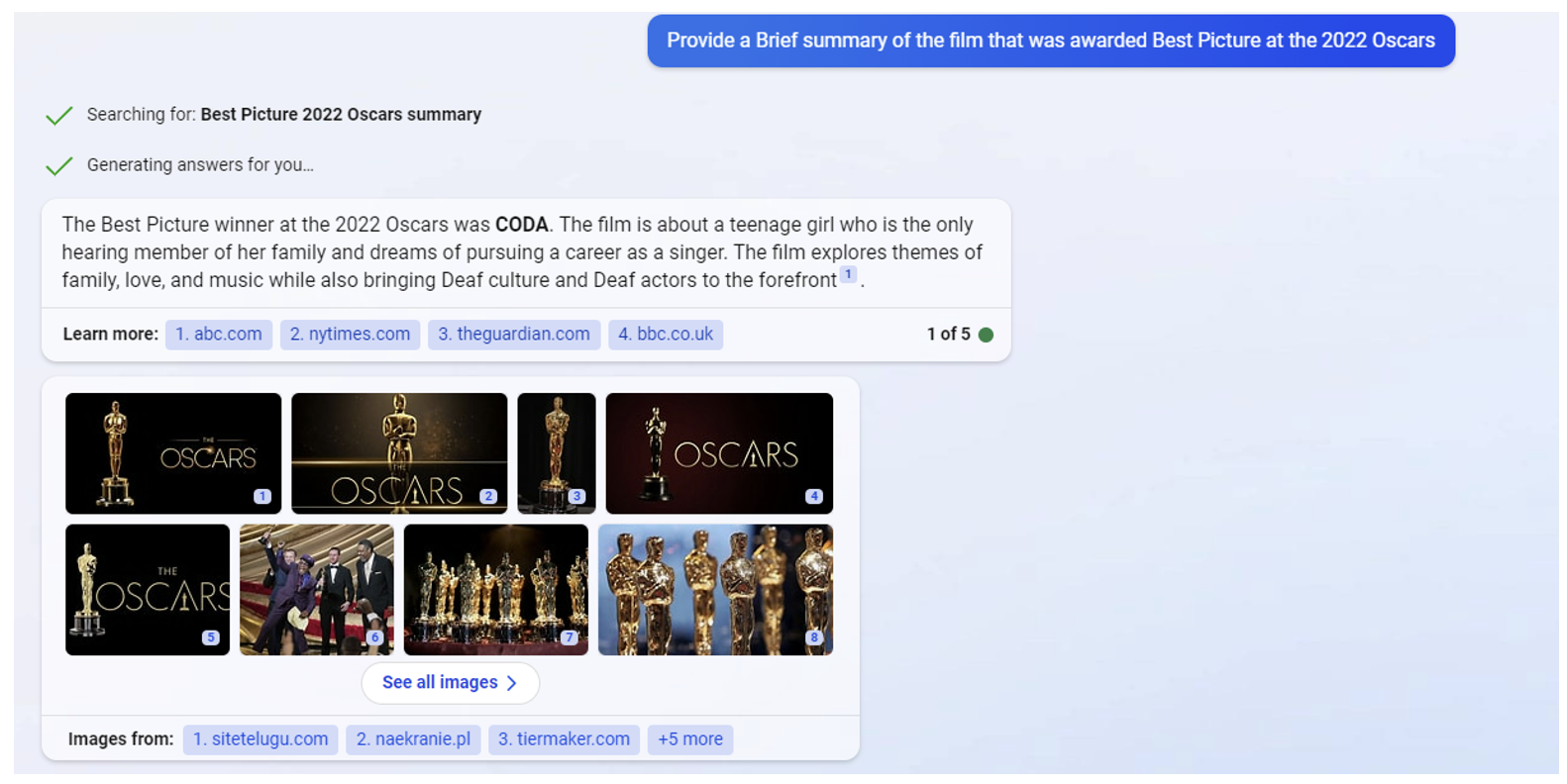
Figure 2: Bing Chat Output - Conversation about recent data
There are also web browsing plugins that let you easily integrate LLMs in browser plugins. Alternatively, OpenAI itself offers a plugin for ChatGPT Plus subscribers.
LLM Augmenters
Let’s now explore some solutions that aim to solve the problem of questions and answers about documents.
- LlamaIndex, a data framework that connects LLMs to enterprise data. It offers data connectors, indexing, and a query interface. Although this post won't delve into its details, it is a framework that is gaining traction in the community.
- DocsGPT, which offers a Chat interface for answering questions about documentation.
- PrivateGPT, a solution that focuses on privacy. It is able to answer questions about documents without requiring an Internet connection.
The latter two solutions will be briefly tested by asking about insights on the “GPTs are GPTs: An early look at the labor market impact potential of large language models” paper from OpenAI, which came out in 2023.
DocsGPT
The setup is very simple. You just need to clone the project; create a .env file and add your OpenAI API key; then build and run a docker-compose command, as pointed out by the official GitHub repository. The default model used is GPT 3.5. There is also a Live preview version where you can test the tool without installing it. As a Pro member, you can use GPT-4.
DocsGPT supports some file formats, such as PDFs, TXT, MD, and others. From the UI, you can upload a file, which is limited to 10MB for the preview version, then select the document of your interest in the drop-down and ask questions about it. You can also pre-train on any document. You have the option to host DocsGPT locally and use other models outside of OpenAI in case you have the computational resources required to run these large models.
Here’s an example:

Figure 3: DocsGPT with GPT3.5 Output – Conversation on OpenAI’s Paper
PrivateGPT
To run it, you need to create a models folder in your project’s directory; download a LLM based on LlamaCpp or GPT4All and move to that folder (ggml-gpt4all-j-v1.3-groovy is the default); then place documents in a source_documents folder; run a ingest python script to parse the documents, create the embeddings and store them in a vector database. It should take a few minutes to create the embeddings. Finally, you can run the privateGPT script, which uses the local LLM you configured beforehand. For a laptop, this should take some minutes to complete the answer.
PrivateGPT supports a wide range of file formats, including PDF, DOCX, PPT, EPUB and HTML, and others. You can easily drop new documents in the source_documents directory, then add them to the vector database with the ingest script. You can even run it without being connected to the internet. Since the focus of privateGPT is running models optimized for privacy locally, you should not expect the same level of results from larger models, such as GPT 3.5.
Here’s an example:
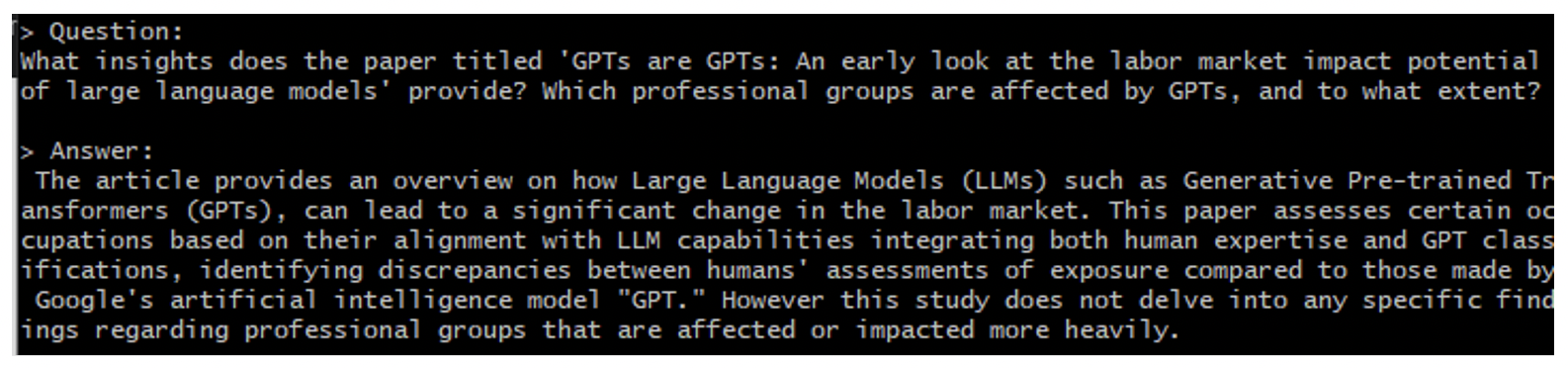
Figure 4: PrivateGPT with GPT4All-J Output – Conversation on OpenAI’s Paper
Key Takeaways
Despite ChatGPT capturing public attention, there are a plethora of other models, extensions, tools, and frameworks that are not getting enough attention amidst the amount of information available. This post explored some approaches for answering questions about documents outside of a LLMs’ training data, which would not be possible to do by LLMs alone. To address this issue, some options were briefly tested, such as using search engines, browser plugins and frameworks like DocsGPT and PrivateGPT. With new models and tools being made available every week, we can expect more widespread usage of these in many different use cases.
Acknowledgment
This piece was written by Daniel Pinheiro Franco, Innovation Expert at Encora’s Data Science & Engineering Technology Practices group. Thanks to João Caleffi for reviews and insights.
About Encora
Encora has been using Generative AI technologies to increase productivity, improve the quality of software deliverables and effectively address client’s needs. Contact us to learn more about our Generative AI and software engineering capabilities.

