As data becomes the lifeblood of modern enterprises, efficient data processing and transformation are critical for generating valuable insights. Snowflake, a leading cloud-based data warehousing platform, empowers data professionals with advanced tools and features to ingest, transform, explore, and analyze enterprise-scale data. Among these, Snowpark Python Worksheets provide an innovative way to leverage Python's data processing capabilities within Snowflake natively.
These capabilities help data engineers and analysts to implement critical data-related functionalities such as the below within their Snowflake accounts natively:
- Data validation and quality
- Data governance and security
- Analysis and exploration of data
- AI and ML models for large and complex data sets
- Data security features without moving data from Snowflake
- Modern and unified data ingestion and processing infrastructure for large-scale data
- Automated, scalable, and robust workflows to provide data to analysts and engineers
- Loading and transforming structured, semi-structured, and unstructured data
In this article, let us explore Snowflake's capabilities that help with high-quality test data generation, crucial for data validation tasks and quality assurance in large-scale data processing platforms/services.
What is Snowpark?
Snowpark allows data engineers to query data and write data applications inside Snowflake with languages other than SQL, using a set of APIs and DataFrame-style programming constructs in Python, Java, and Scala. These applications run on and use the same distributed computation on Snowflake's elastic compute engine as your SQL workloads.
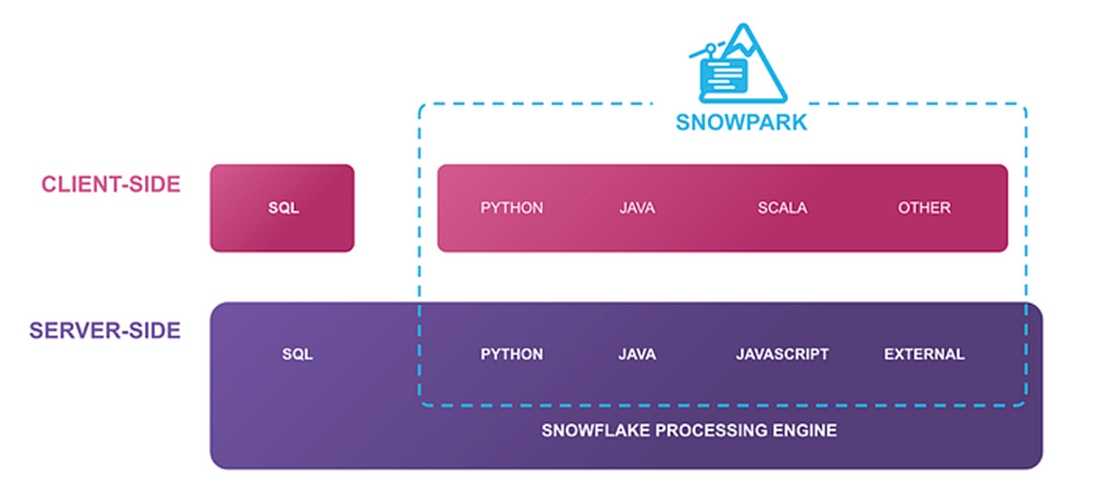
Operationalizing Snowpark Python: Part One | by Caleb Baechtold | Snowflake | Medium
Client Dataframe API
The Client Dataframe APIs allow you to create queries and work with data using the familiar DataFrames approach. They use a smart technique called push-down processing, which connects to Snowflake's strong computing engine to make things faster and manage more data smoothly.
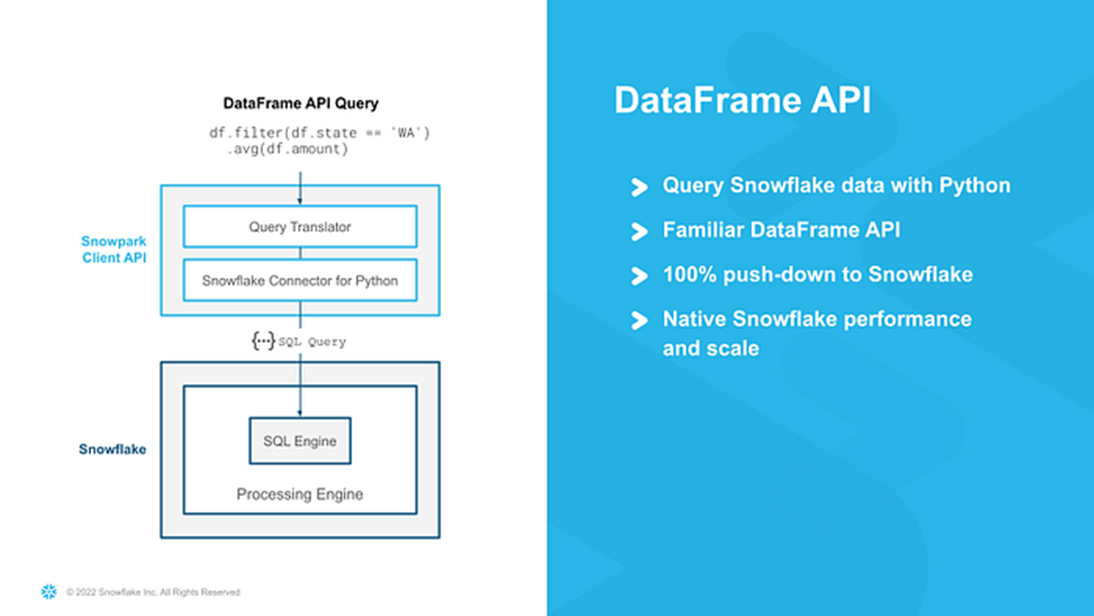
Operationalizing Snowpark Python: Part One | by Caleb Baechtold | Snowflake | Medium
User-Defined Functions (UDFs) and Stored Procedures
The Snowpark Python server-side runtime allows you to write Python Stored Procedures, User-Defined Functions (UDFs), and User-Defined Table Functions (UDTFs). Once deployed into Snowflake, these can be invoked from any Snowflake interface. They execute in a secure Python environment on Snowflake virtual warehouses.
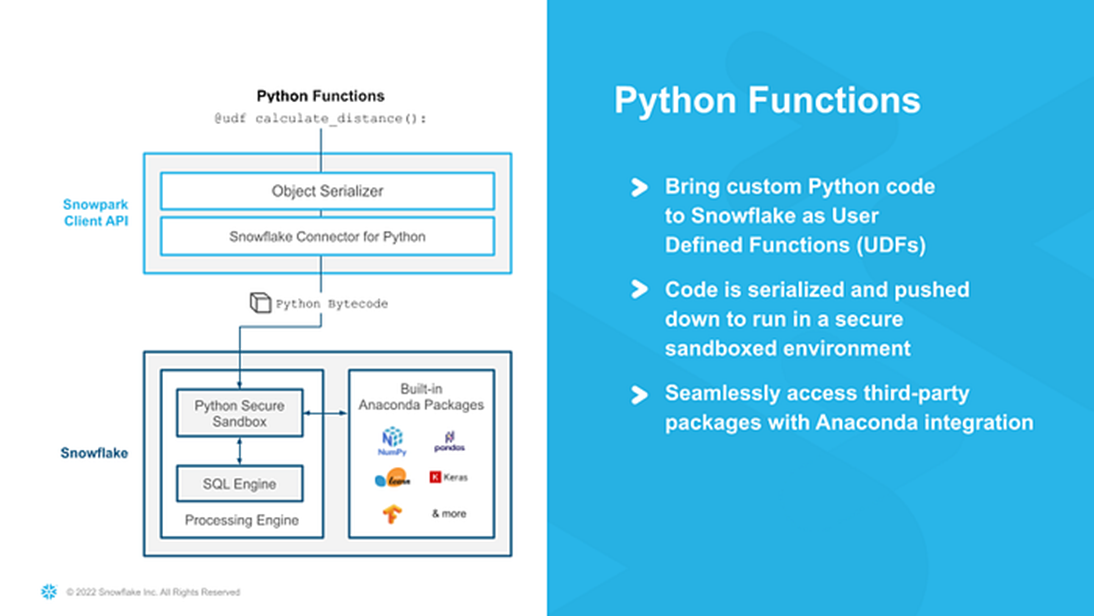
Operationalizing Snowpark Python: Part One | by Caleb Baechtold | Snowflake | Medium
Learn more about Snowpark here.
What are Python Worksheets?
Snowsight introduces a new feature: Python worksheets. These worksheets help users get started with Snowpark quickly. Inside Snowflake, users can develop data pipelines, ML models, and applications without an additional IDE (development UI) for Python. Additionally, these worksheets can be transformed into procedures, allowing you to schedule your Snowpark applications. Learn more about Python Worksheets here.
Steps to Start Working with Python Worksheets
Learn the basic steps to work with Python Worksheets here.
Test Data Generation at Scale
One of the critical components of any software product or service is to assess behavior and performance under various conditions. Access to real-world data is not always a privilege that data engineers or testers enjoy. Either the data will be masked for security reasons, or it will be a limited sample or low volume from test systems.
Generated test data, however, simplifies some of these frequent roadblocks. Test data generation is pivotal in delivering reliable data solutions in the digital age where data-related decisions are prominent. Some of the highlights of using the test data are as follows:
- Realistic Simulation: Realistic simulation helps identify potential flaws, vulnerabilities, and bottlenecks in the data volumes and patterns. The data application can be assessed thoroughly by mimicking real-world scenarios and conditions, making it ready for an actual operation.
- Edge Case Testing: By generating test data that includes extreme values, uncommon inputs, high volume, and boundary conditions, data engineers ensure that the data solution manages the velocity, volume, value, variety, and veracity of real production data.
- Performance Evaluation: By subjecting the data platform to varying workloads and data volumes using test data, data engineers can identify potential performance bottlenecks, resource overconsumption, or slow responses.
- Data Privacy and Security: In today's digital landscape, data privacy and security are paramount. Generating test data that closely resembles real-world data – without exposing sensitive information – allows data engineers or analysts to assess security measures, encryption, and access controls. It ensures that the data platform can protect sensitive data from potential breaches or unauthorized access.
- Reducing Data Dependency: Data engineers and testers face challenges due to data availability constraints. These constraints can arise from limited access to real-world data, privacy and security concerns, or the absence of high-volume data in test environments. Generating test data helps overcome these obstacles.
- Regression Testing: A well-curated set of high-volume test data allows data engineers to perform thorough regression testing, ensuring that existing analytical functionalities remain intact. At the same time, new features are integrated into the data platforms.
- Automated Testing: Generating diverse test data at scale streamlines the automation process, making it easier to cover a broad spectrum of data scenarios efficiently.
- Cost and Time Efficiency: By generating test data, data engineers can expedite the testing process, identify issues earlier in the data lifecycle, and reduce the time and cost associated with data product development.
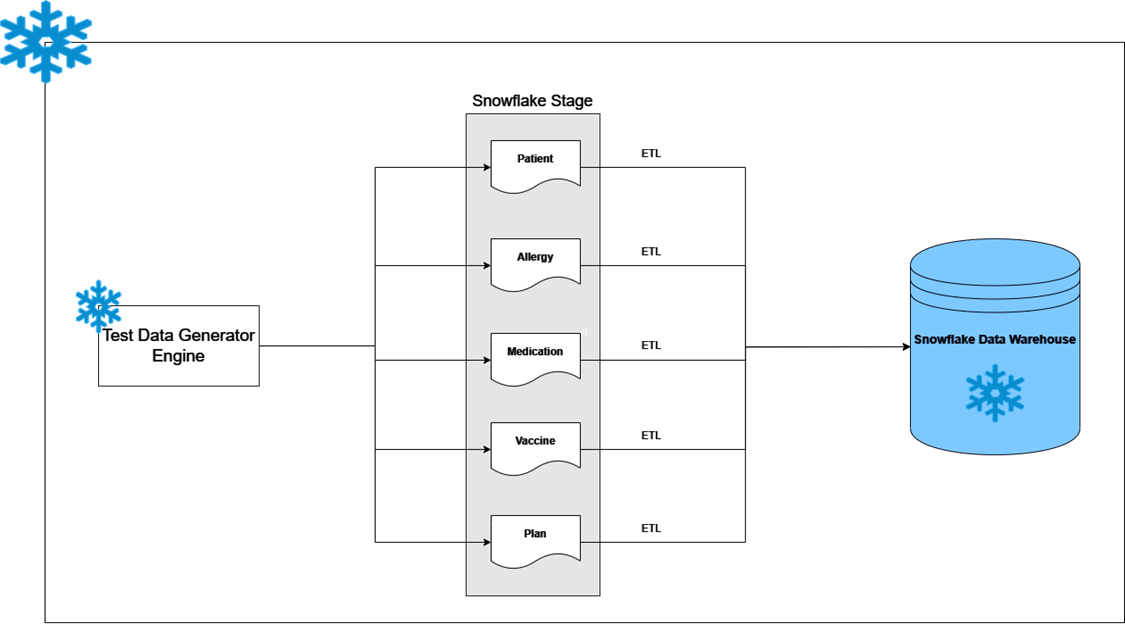
In a real-world scenario, data would be consumed from the Healthcare Application to an Enterprise Data Warehouse as follows:
- The application generates the data for entities like Patients, Allergies, Medication, etc.
- A replication tool captures CDC data.
- An ETL tool sends the CDC data to the Snowflake Data Warehouse.
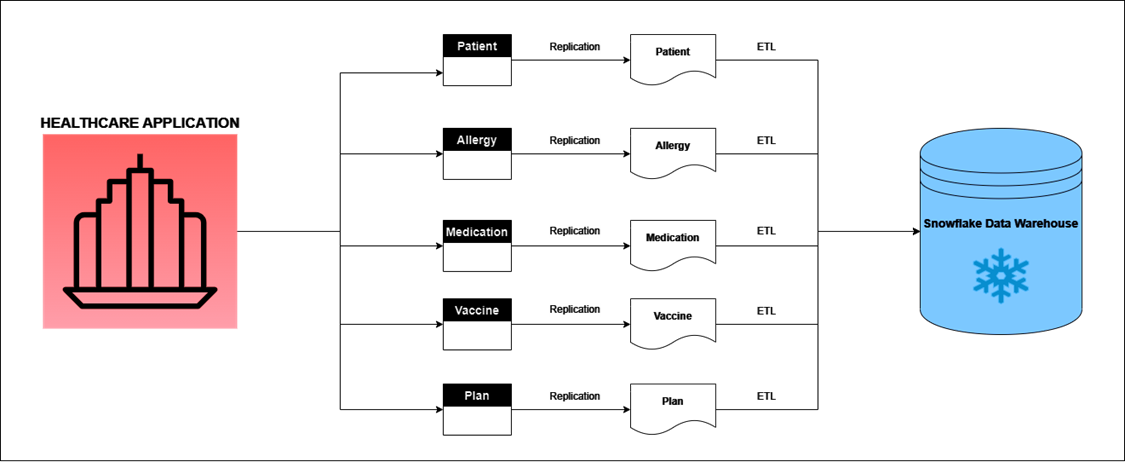
For data engineers or testers, a test data generation engine can replace the actual Healthcare application and replicate a similar process as follows:
- The test data generation engine generates data mimicking CDC data and persists in a snowflake staging table.
- An ETL tool sends the CDC data generated by the test data generation engine to the Snowflake Data Warehouse.
The Program Explained
Now that we have covered all the primary premises, let us generate sample data for the patient entity and store it in a Snowflake table. We will use Python's Faker library to create 100 sample patient data items, such as First Name, Last Name, and Address. Then, we'll store this data in a Snowflake table.
The Import Statements
|
import snowflake.snowpark as snowpark import pandas as pd from faker import Faker from random import randint |
The Handler Function
The handler function is set to "main" by default. You can change this in the worksheet's Settings section.
|
def main(session: snowpark.Session): # Insert your code here |
The Next Steps
Use the Faker package to generate random User Information. For this example, we will generate 10 sample records and store them in a panda DataFrame.
|
fake = Faker() patient = pd.DataFrame() for i in range(0, 100): patient.loc[i,'Id']= randint(1, 1000) patient.loc[i,'First_Name']= fake.first_name() patient.loc[i,'Last_Name']= fake.last_name() patient.loc[i,'Address']= fake.address() patient.loc[i,'Zip']= fake.zipcode() patient.loc[i,'Phone_number']= fake.phone_number() patient.loc[i,'Email']= str(fake.email()) patient.loc[i,'SSN']= str(fake.ssn()) |
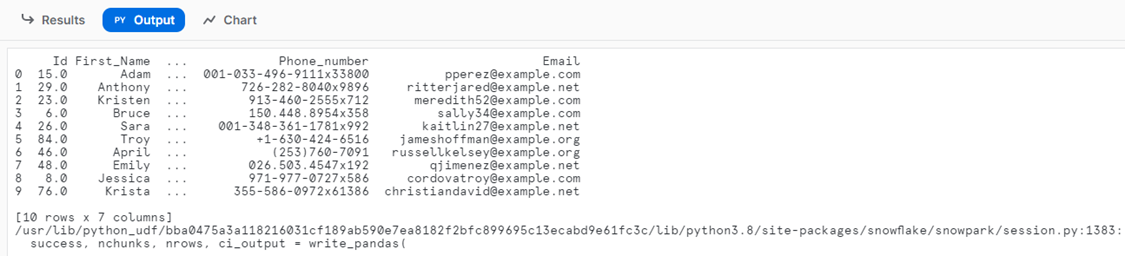
The Output Panel
The output panel for a Python worksheet should be used to review standard outputs or error messages. The functions that write to the console, e.g., print(), or those that print a DataFrame, e.g., the show method of the DataFrame class. The output will appear after all the Python processes finish running.
|
print(patient) |
The Results Panel
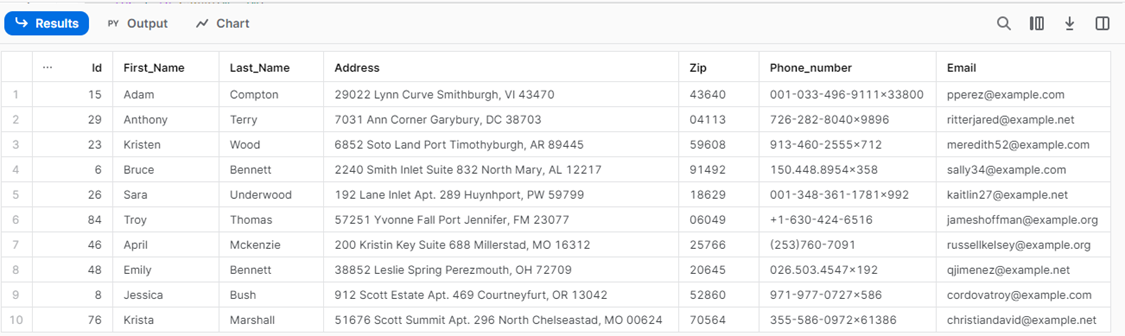
Using the pandas DataFrame created earlier, store the generated information in the Snowflake Dataframe. Use the save_as_table method to write the data to a snowflake table. We will use the return keyword to view the results in the Results pane.
|
df = session.create_dataframe(patient) df.write.mode('overwrite').save_as_table('patient') return df |
The Complete Program:
|
import snowflake.snowpark as snowpark import pandas as pd from faker import Faker from random import randint
def main(session: snowpark.Session): fake = Faker() patient = pd.DataFrame() for i in range(0, 100): patient.loc[i,'Id']= randint(1, 1000) patient.loc[i,'First_Name']= fake.first_name() patient.loc[i,'Last_Name']= fake.last_name() patient.loc[i,'Address']= fake.address() patient.loc[i,'Zip']= fake.zipcode() patient.loc[i,'Phone_number']= fake.phone_number() patient.loc[i,'Email']= str(fake.email()) patient.loc[i,'SSN']= str(fake.ssn()) print(patient)
df = session.create_dataframe(patient) df.write.mode('overwrite').save_as_table('patient') return df |
Stored Procedure
Finally, Snowflake gives an option to deploy this as a store procedure. Snowflake provides the Deploy button on the Python worksheet.
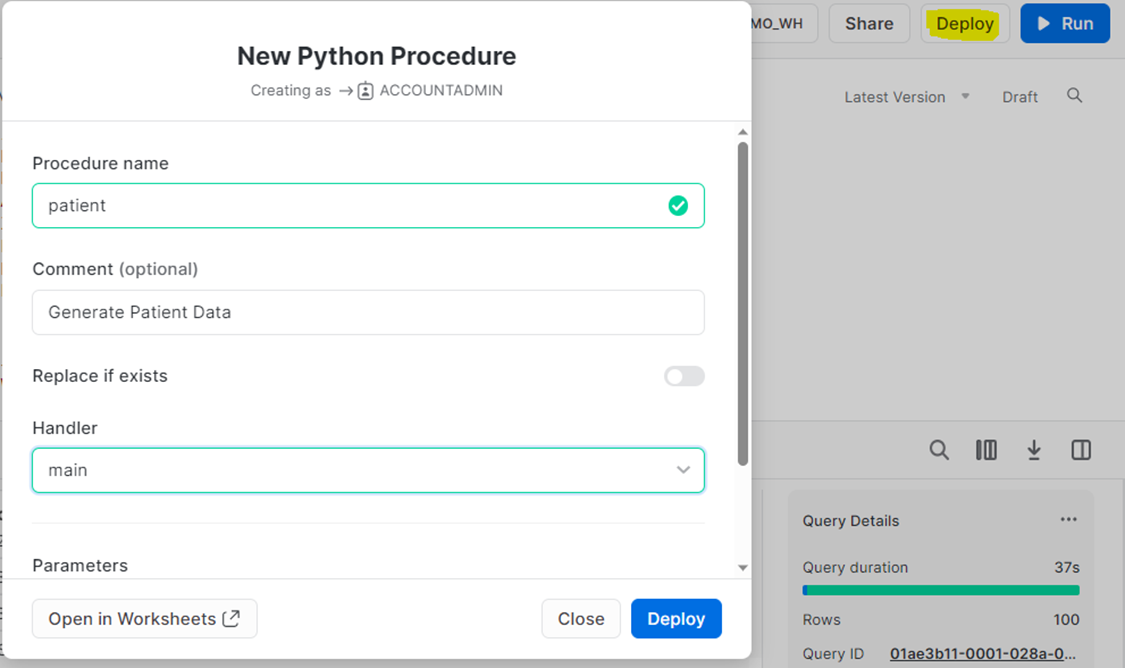
You can schedule this stored procedure to generate data regularly using Snowflake tasks. Below is an example of creating a daily task to create and persist patient entity data.
|
create or replace task patient_table schedule = 'using cron 00 00 * * * utc' user_task_managed_initial_warehouse_size = 'xsmall' as call patient(); |
Test Data Generation Engine
You can replicate the above program for the Patient entity and customize it for different entities. You can place each entity in its own stored procedure and schedule it to run at a specific time. You can also execute it as needed for development or testing activities. Below is a sample flow for the test data generation engine. Following is a sample flow for the test data generation engine.
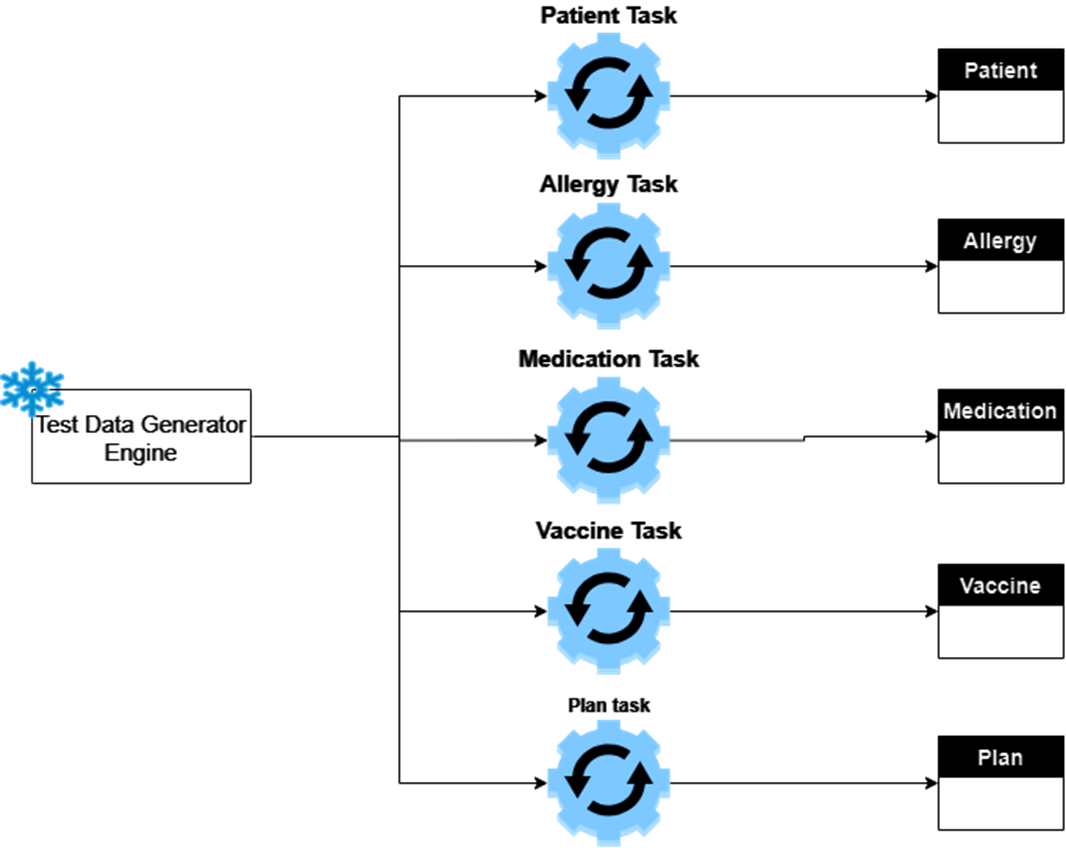
Key Takeaways
Snowflake stands as a game-changing cloud data platform that not only streamlines data migration and modernization but also empowers organizations to fully harness the potential of Python, Java & Scala for advanced analytics and data-driven applications.
Snowflake's seamless integration with Python opens a world of possibilities for data scientists, analysts, and engineers. Python, a versatile and popular data manipulation and analysis programming language, pairs exceptionally well with Snowflake's scalable and high-performance infrastructure.
Snowflake's competence in data migration and modernization, combined with the limitless potential of Python, empowers organizations to break through data silos, uncover hidden patterns, deliver meaningful results at scale, and open doors to unprecedented possibilities in the ever-evolving landscape of data-driven decision-making.
Acknowledgment
This piece was written by Ritesh Muhatte and Kedarnath Waval from Encora.

About Encora
Fast-growing tech companies partner with Encora to outsource product development and drive growth. Contact us to learn more about our software engineering capabilities.

