Neural architectural search (NAS) is a sub field of Auto ML. Automated machine learning (Auto ML) is evolving, and so is NAS. In this blog, we cover the importance & reasons that make NAS a valuable technique, and how Auto ML, and particularly NAS, can solve industry-wide problem of slow & sometimes failed ML implementations. Successful applied machine learning (ML) is hard to come by, and that is where advances in NAS can play an important role and be decisive in the future of ML. Can NAS outperform human designed neural network? To answer that, we need to first understand the recent advances in NAS, along with inner workings.
Auto ML has accelerated "applied machine learning"; typical implementation covers the complete lifecycle, from raw data to inferences from trained models. In general, Auto ML platforms and techniques only require the raw data to be fed. Internally, Auto ML may constitute transfer learning, feature extraction, feature selection, NAS (model selection, hyper-parameter optimization and meta learning) and inferencing.
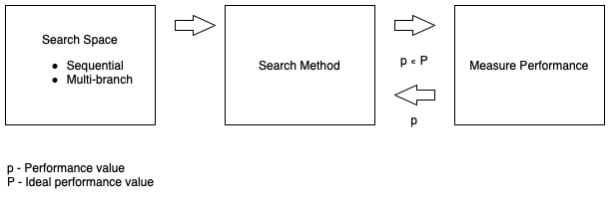
Auto ML avoids biases which can be inadvertently introduced by humans if they were to design the same model and related processes. Models based on Neural Networks (NN) are powerful yet flexible and these models perform well on tasks related to images, speech, and video, among others. The major downside to NN is the complex design and the specialized knowledge required to develop them; this is where NAS is being applied to model these complex NNs to perform better than, if not similar to the ones designed by humans. Overall, NAS finds the optimal architecture from defined "Search Space" using "Search Method" which maximize performance. NAS is under active research; however, it can be broadly grouped into Search Space, Search Method and Performance (Evaluation).
Search Space
Search space aims to find the possible valid NN architectures. These NN architectures could either be sequential wherein output of the layer (l-1) is fed to input of layer l, or a more complex multi-branch architecture where some layers may be skipped. Sequential architecture has a maximum layer limit with any type of layer computations, and may include convolution, pooling, flatten, dense, etc., and related hyper-parameters, weights and biases.
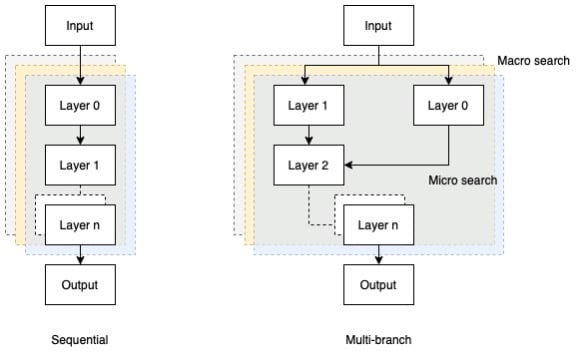
Multi-branch architecture is a more contemporary, yet complex approach where input to a random layer can be an output from single or multiple layers. This approach involves recurrent layers like grugru (Gated Recurrent Units) or RNN (Recurrent Neural Network). Attention mechanisms can be used to skip certain layers. Another approach could be that at layer n, an anchor point is introduced with n-1 information and sigmoid to poll if the previous layers can be connected. Sequential architecture may be more computationally intensive as compared to multi-branch architecture for a similar search-space. Further, such architectures (sequential and multi-branch) can be encapsulated into macro structures, where the outer structure is rigid and the algorithm only searches for inner blocks / cells also known as micro-search. While optimizing performance, both macro and microstructures (multi-level motifs) are searched in hierarchical, cell-based constructs among others.
Search Method
It involves sampling architecture constructs and evaluating them for performance and latency. Here, a lot is in common with searching optimized hyper-parameters. Measure of performance metric can act as a reward for a controller within which an agent does some action (in this case, sample a child network) according to a policy. With subsequent iterations involving trial and error, the controller learns to generate high performance architectures. One approach to search methods could be random search, where child networks are randomly sampled and evaluated. This method does not involve reinforcement learning (RL), but rather a well-constructed random search space can be a very good baseline to improve upon.
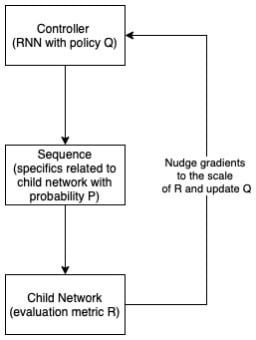
Another widely considered approach makes use of reinforcement, and such search methods may use Recurrent Neural Network (RNN); output of the RNN is a sequence with a SoftMax probability. The RNN acts as a controller, and the output sequence contains specifics to construct a network. If instead a CNN was used, then the sequence will consist on filter / stride height & width along with related parameters. A child network is generated based on the information in sequence and further evaluated. Here, RNN parameters act as the policy, and the information in sequence as action, while the evaluation metric of the model acts as the reward. Based on the evaluation metric, the policy is updated in a way to maximize the performance, thus improving upon the generated architectures subsequently.
Search spaces are discrete, and one architecture differs from another; when we apply continuous relaxation to a discrete search space, such spaces can be optimized using gradient descent. Differentiable operations consider both architectural parameters and weights into one model and solve it as a gradient descent optimization.
Evaluation (Measure performance)
In order to update the policy of the controller, we need to estimate or measure the accuracy of every child architecture. The performance metric acts a reward for the controller to update the policy. The proposed child architecture is trained and converged; it is evaluated on the validation data to compute the reward. Apart from accuracy, latency and complexity (e.g., number of parameters) can also be a proxy to evaluate performance. To train-converge-evaluate every child network is an overwhelming task and can be very expensive; although, if carried out, it’s very hard to out-perform such resultant architectures. Another approach would be to re-use some of the parameters in previous learnings. For each child network instead of training from scratch, the previous seen weights are reused using a RL agent. Due to inherited weights, the subsequent trainings are light-weighted.
Some of the future research in NAS will involve evaluation techniques, which looks beyond accuracy or its derivatives. Differentiable NAS makes use of weight and parameter sharing methods along with continuous relaxation of the search space and making use of gradient-descent optimizations. Such Differentiable NAS has out-performed methods based on RL controller in much lesser search time in some specific cases. ENAS (Efficient neural architecture search) is an improvement upon traditional NAS, where the controller within ENAS searches for an optimized sub-graph within a large graph. The controller policy is updated to maximize the reward. Optimized sub-graphs share parameters.
In summary, Auto ML has accelerated applied machine learning, and NAS is a core component of Auto ML.

About Encora
Fast-growing tech companies partner with Encora to outsource product development and drive growth. Contact us to learn more about Auto Machine Learning and Neural Architectural Search


