You've undoubtedly heard the buzz surrounding OpenAI's GPT-4. You might have even dabbled with it, integrating its capabilities into your daily tasks. But now, as you delve deeper, you're on the lookout for more advanced use cases. You’re probably wondering if you could leverage GPT-4 capabilities to achieve tasks related to cloud-based applications and perhaps, looking to achieve more cloud-strategic goals. Have you ever wanted a way to easily inventory your cloud resources? Perhaps you're considering reviewing your cloud attack surface? Or are you pondering effective planning for cloud costs? All of the above?
As we all know, working with a vast amount of data across multiple resources in the cloud can be daunting. Being able to effortlessly query your AWS account and have the necessary insights at your fingertips can streamline your operations significantly. In this post, we will go over a proof of concept of how you can easily leverage GPT-4 to achieve your cloud strategic goals far more easily than ever before.
So, why should you care about this? Leveraging AI-powered tools can not only improve your efficiency but also enable a more in-depth understanding of your cloud infrastructure, regardless of your current state. With clear insights, you can manage your resources better, make informed decisions, optimize costs more effectively, and ultimately, get key insights about your cloud workloads that will effectively achieve your strategic cloud objectives. Whether you're a seasoned cloud professional, a cybersecurity professional, a CTO, or a newcomer to the tech scene, this post is for you.
Proof of concept components

Solution Architecture - Image by Author
To achieve our goal, we need an easy way to query cloud services and process the output automatically. The main components for our proof of concept are:
- Steampipe.io. An open-source tool for querying cloud APIs in SQL. This excellent tool will serve as the foundation of our experiment.
- Azure OpenAI Service. Azure OpenAI Service provides REST API access to OpenAI's powerful language models, including GPT-4. The main engine behind our experiment. We are taking advantage of Encora’s Microsoft partnership to be part of the Azure OpenAI Service that is currently offering limited access.
- LangChain. A Python framework for developing applications powered by language models. This framework will serve as the glue, or better said, chain together the cloud APIs and GPT-4 for retrieving key insight.
Supporting components for the experiment include:
- AWS Account. We’re leveraging an AWS account for two purposes – first, as the target cloud for all our querying; and second, as the platform to run our application proof of concept. The application leverages the serverless framework as all components are running in serverless services inside AWS. This also allows us to have a portable solution, following an infrastructure-as-code approach.
- Slack. A productivity platform made for easy communication. We are leveraging Slack (and a Slack application) as the input interface for our experiment, as we want to keep things as simple as possible.
In a nutshell, we want to query an AWS account using natural language in order to retrieve key insights, all powered by GPT-4 and LangChain – sounds pretty exciting!
Putting it all together
To get started, we will need the following requirements:
- Set up an AWS account. You can certainly leverage the AWS Free Tier for all the components in this experiment.
- Set up steampipe. You can easily set up steampipe with your favorite cloud in a few minutes. In this case, we will choose AWS.
- Set up the OpenAI Service. If you have the opportunity, I recommend you use Azure Open Service with its remarkable enterprise features, but you can also use OpenAIs native service to achieve the same goal.
- Set up Slack + Slack app. This is an optional step, as you can also run this from the Python command line, but it’s recommended if you plan on sharing access to this proof of concept with your peers!
Once everything has been set up, you can start testing from Python using the following snippet as a reference.
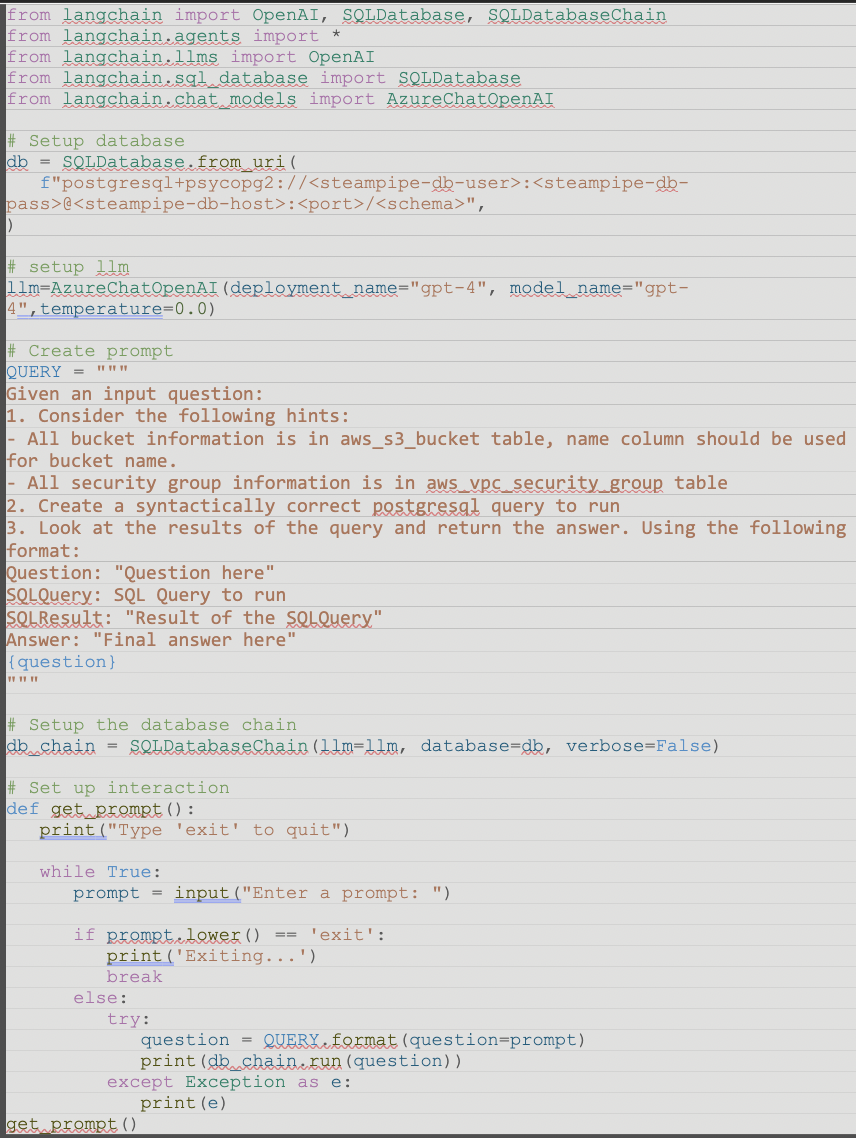
Consider the above snippet expects the environment variables to be setup in advance namely OPENAI_API_VERSION, OPENAI_API_KEY, and OPENAI_API_BASE. You can get these from your OpenAI Service deployment.
This basic example will allow you to execute basic queries without too much hassle, using natural language:
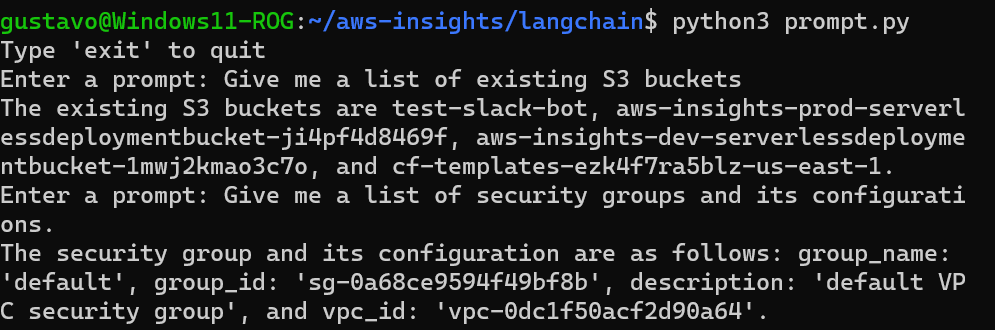
Pretty impressive so far, right? Now, let’s extend the functionality of the code by applying the following techniques:
- Leveraging LangChain, you can “pre-load” specific tables and rows to give more context to GPT-4, which in turn will give better insight into the responses. The downside to this approach is that GPT-4 will use more tokens, so it can potentially add more costs, depending on the size of your schema and rows.
- You can customize the prompt to give “hints” for details that are specific to your database schemas, for example. This can potentially be a better approach that pre-loading tables as far as cost savings go.
- If you want to debug the execution, you can turn on verbosity by setting the “verbose=True” flag in the SQLDatabaseChain setting, which will show the SQL generated, as well as the raw output.
With the proper techniques applied, you can create an advanced application that can answer anything you have in mind. Here is an example advanced use case, when everything is put together, using Slack as the input platform:
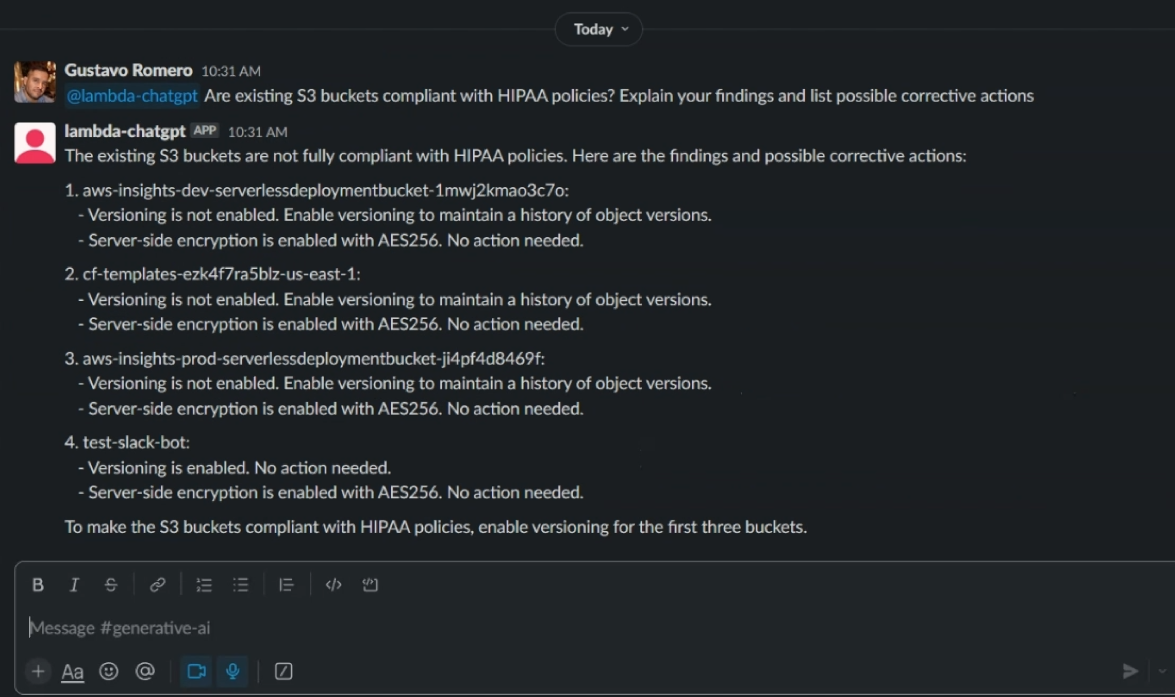
In this example, we are querying about HIPAA compliance for all the existing S3 buckets in the AWS account and asking to return possible corrective actions for non-compliance. The response is generated in under a minute. Let’s see what is happening under the hood with verbosity enabled:
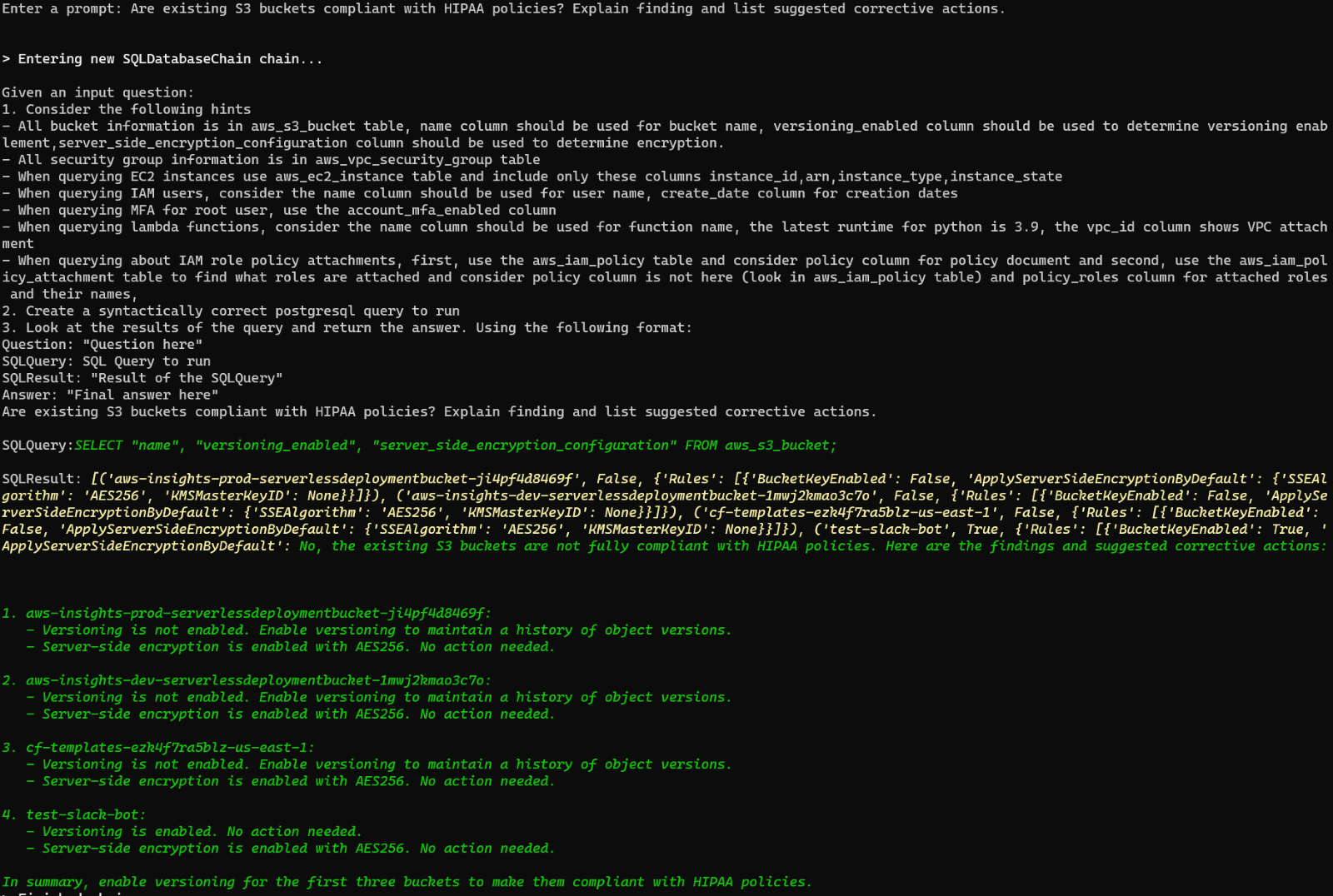
As you can see, we used a fine-tuned prompt with a few hints. The SQL prompt was generated and executed against the steampipe database. Then, the raw SQL output was sent to GPT-4 and interpreted appropriately.
Now let’s play with potential cost savings, let’s see what we can find:
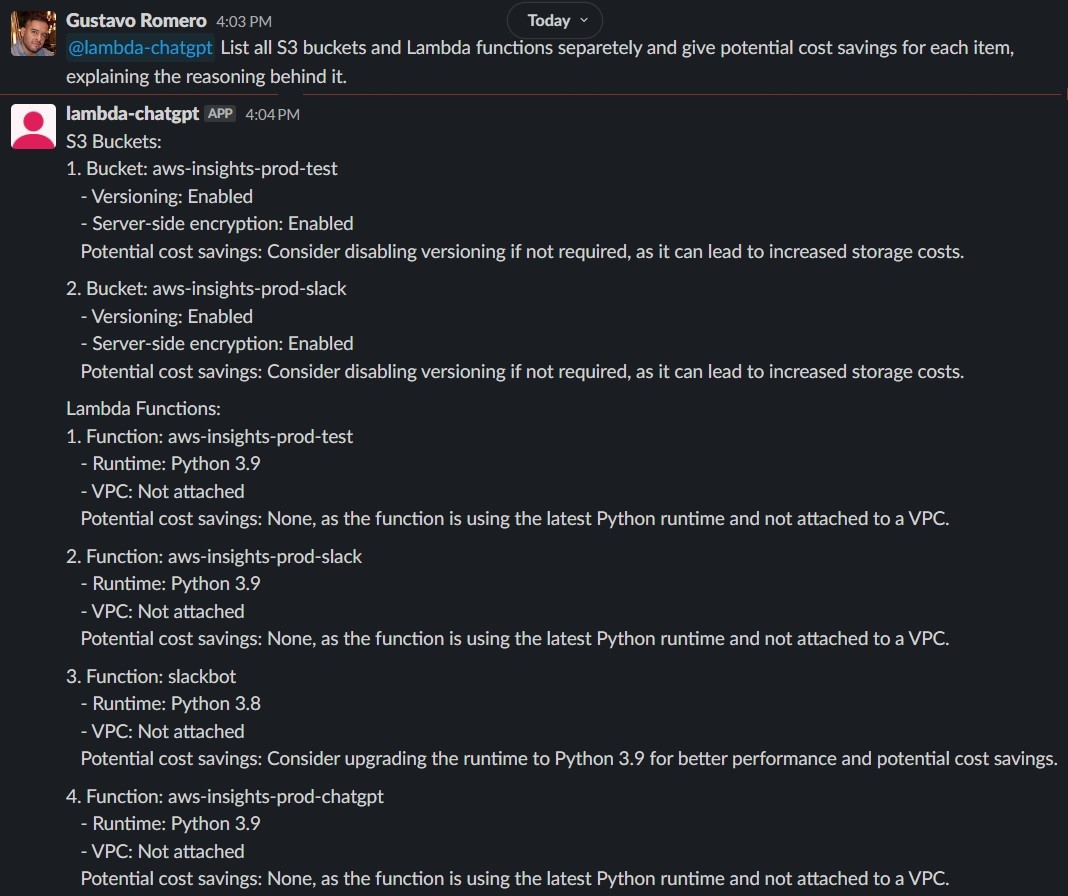
This is an interesting insight indeed, but it raised some questions– why does GPT-4 consider that not attaching a lambda function to a VPC can potentially save costs? Reading the AWS official documentation, turns out that there are indirect costs of using lambda inside a VPC, such as NAT Gateways.
Conclusion
In this proof of concept, we demonstrated how easy is to build GPT-4-powered applications and provide instantaneous insight using natural language, which can revolutionize our approach to cloud strategy, making it an incredibly user-friendly solution that can meet the complex demands of any organization.
Remember, the use cases discussed in this post are just the tip of the iceberg. Imagine the possibilities when you apply this technology to other aspects of your organization's cloud operations. By stepping into the world of AI-Augmented Observability with GPT-4, you are unlocking a powerful tool that can transform how you understand and manage your cloud infrastructure. Are you now ready to kickstart your journey with AI-Augmented cloud insights?

About Encora
Fast-growing tech companies partner with Encora to outsource product development and drive growth. Contact us to learn more about our software engineering capabilities.
Author Bio
Gustavo Romero
Principal DevOps Engineer
Gustavo Romero is a seasoned Lead Cloud / DevOps engineer with a focus on AWS, Azure Cloud and security compliance over the last 12 years. A true cloud champion, Gustavo has earned every associate & professional level AWS certification, and he also holds several expert level Microsoft Azure Certifications.
Gustavo’s broad client experiences include migration of on-premises applications to the Cloud, implementation of CI/CD processes, architecting cloud native applications, container orchestration, creation of “Infrastructure as Code” templates for infrastructure deployments, implementation of SOC 2/ISO 27001 security controls for SaaS applications, and broad deployment of automation strategies to drive scalable impacts for clients.
Gustavo is a passionate technologist, always looking for new challenges.

